BERT模型有多少参数?
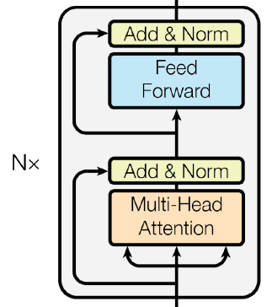
bert 大模型 BERT仅使用Transformer的encoder部分,encoder由多个Transformer block堆叠而成,每个block的内部结构如下图所示:
与原始Transformer使用token嵌入和位置编码相加作为输入不同,BERT使用token嵌入、segment嵌入和position嵌入三个向量相加作为最终输入,如下图所示:
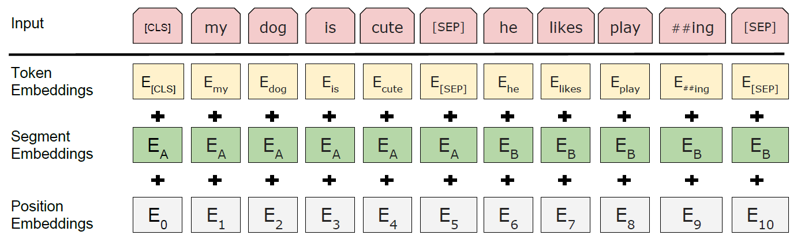
以BERT-base为例,模型使用的词表包含30522个token,每个token由768维向量表示,因此token嵌入矩阵的形状为[30522, 768],参数量:
30522 * 768 = 23440896
segment嵌入用于表示某token属于句子A还是句子B,因此segment嵌入矩阵的形状为[2, 768],参数量:
2 * 768 = 1536
BERT-base输入的最大序列长度为512,因此position嵌入矩阵的形状为[512, 768],参数量:
512 * 768 = 393216
三个嵌入相加后,经过一层LayerNorm,包含一个gain向量和一个bias向量,形状均为[768],参数量:
768 * 2 = 1536
因此,BERT-base输入层的参数总量: 23440896 + 1536 + 393216 + 1536 = 23837184
输入层之上,BERT-base堆叠了12个Transformer block,每个block内部又有muti-head attention和feed-forward两个子层。在multi-head attention子层,BERT-base有12个注意力头,每个头对应的Q、K和V矩阵的形状均为[768, 64],偏置形状为[64],单个注意力头的参数量:
(768 * 64 + 64) * 3 = 147648
12个注意力头的参数总量:147648 * 12 = 1771776
每个注意力头输出一个64维向量,拼接12个注意力头的得到768维向量,然后用一个dense层变换,变换矩阵形状为[768, 768],偏置形状为[768],参数量为:
768 * 768 + 768 = 590592
Feed-forward层把multi-head attention层的输出做两次映射:一次升维,一次降维。升维映射矩阵形状为[768, 3072],偏置为[3072],降维映射矩阵形状为[3072, 768],偏置为[768],参数量:
(768 * 3072 + 3072) + (3072 * 768 + 768) = 4722432
在multi-head attention和feed-forward两个子层之后,各有一个LayerNorm层,包含gain和bias两个向量,形状均为[768],参数量:
768 * 2 * 2 = 3072
因此,一个Transformer block的参数总量:1771776 + 590592 + 4722432 + 3072 = 7087872
BERT-base共有12层block,12层参数总量: 7087872 * 12 = 85054464
下图展示了BERT-base的基本结构和全部参数:
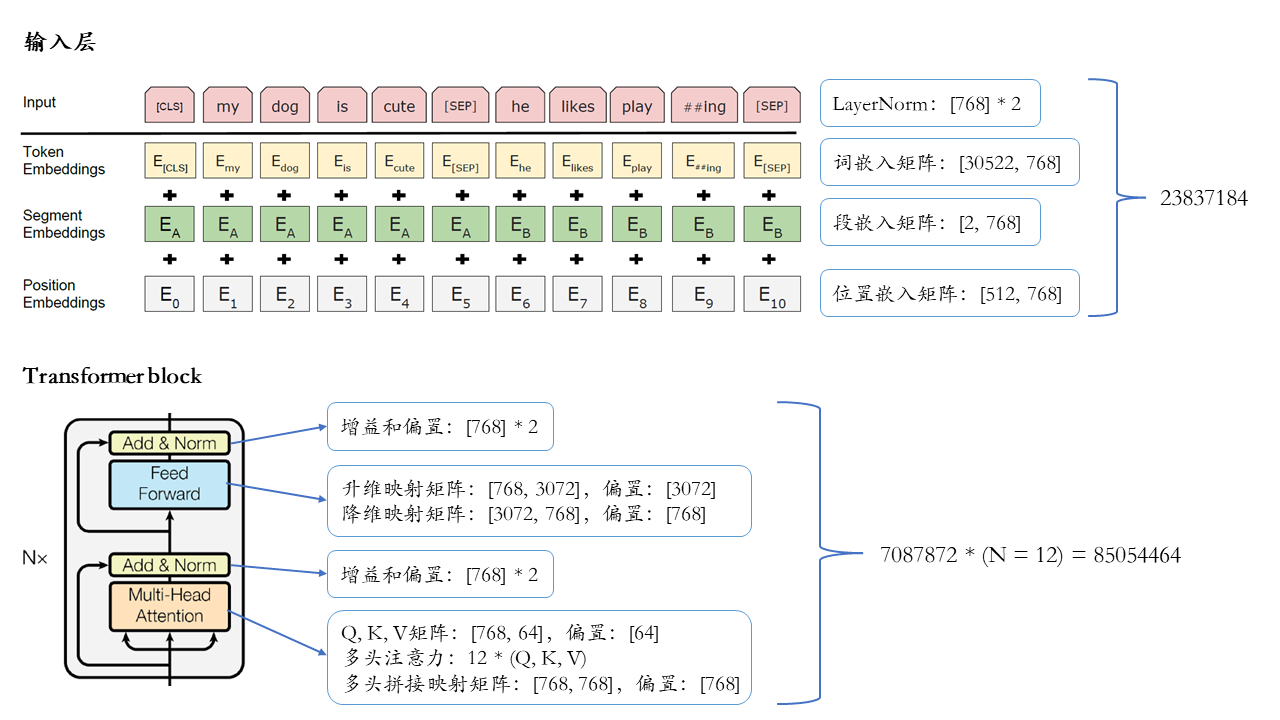
综上,BERT-base的参数总量: \(23837184 + 85054464 = 108891648 \approx 109M\)