多语言预训练模型-Multilingual BERT
bert 大模型 神奇的跨语言泛化能力
Multilingual BERT是BERT的多语言版本,训练方法与BERT一致,包含12层transformer。不同之处在于训练语料:多语言BERT使用的语料是包含104种语言的Wikipedia,训练时共享同一个包含所有语言的WordPiece词表。
把原始的BERT称为EN-BERT,多语言版本的BERT称为M-BERT。二者相比,M-BERT的特殊之处在于可以零样本跨语言迁移:在一种语言上标注和微调,在另一种语言上测试,效果却好到令人惊讶。先来看它在NER和POS两个任务上的表现:
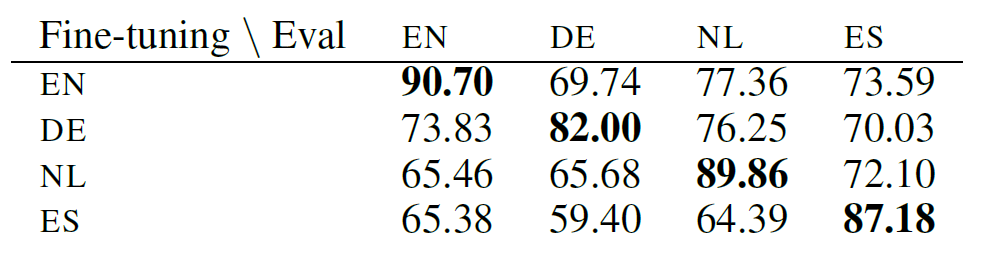
左图是M-BERT在CoNLL上的表现,右图是在UD数据集上的表现。可以看出,如果微调和测试是同一种语言,得到的F1是最高的。如果微调和测试不是同一种语言,F1虽然有所下降,但依然是个不错的结果。例如,在NER任务上,用英语(EN)微调,用荷兰语(NL)测试,仍可以得到77.36这一较高的F1。这一现象表明,M-BERT具有跨语言的泛化能力。那么,产生这一特殊能力的原因是什么?
词表记忆的影响微乎其微
一个最直接的猜测是“词表记忆”。因为一些英语单词的拼写方式与荷兰语、西班牙语等语言非常接近,它们的词表之间可能有重合。例如,微调语料是英语,测试语料是西班牙语,模型在英语上微调时可能就已经见过并记住了西班牙语测试语料中的部分词汇。在NER任务中,不同语言之间的实体往往很相似,因此不妨看看训练语料中的实体word piece与测试语料中的实体word piece之间的重合度。令\(E_{train}\)和\(E_{eval}\)分别表示训练集和测试集中实体的word piece集合,定义实体重合度:
$$ overlap= \frac{\left |E_{train}\cap E_{test} \right |}{\left |E_{train}\cup E_{test}\right |} $$
在一个包含16种语言的数据集上,两两组合不同语言,测试语言的重合度和模型跨语言迁移能力之间的关系。16种语言共有\(C_{16}^{2}=120\)种组合,分别测试M-BERT和EN-BERT在NER任务上的F1,得到下图:
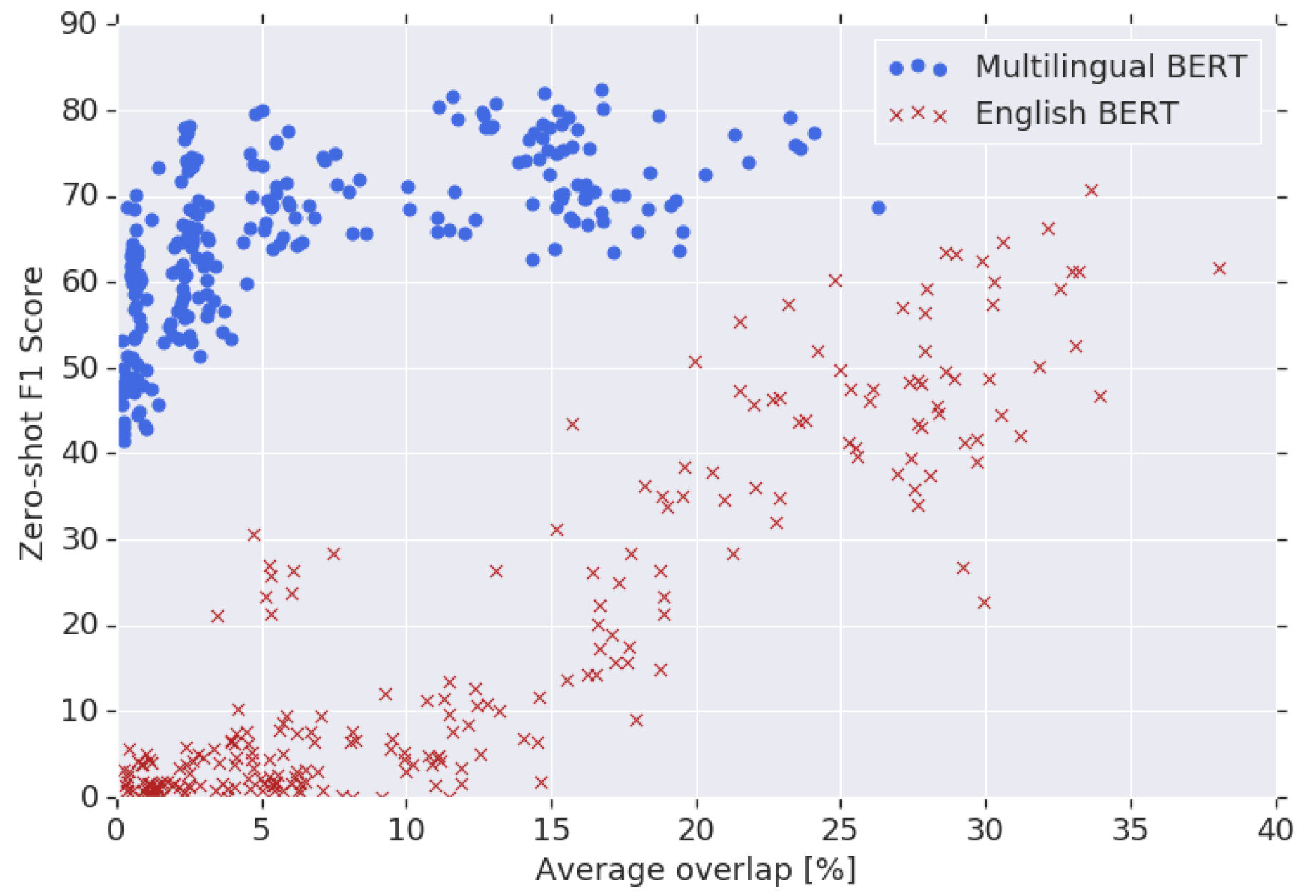
从上图可以看出,EN-BERT(红色)的F1受实体重合度影响较大:当重合度增加时,F1也有增加的趋势;当重合度接近0时,F1也趋于0。这说明EN-BERT的跨语言迁移能力主要来自“词表记忆”。M-BERT(蓝色)的F1受实体重合度的影响很小,基本位于40%-70%的区间内,变化相对平缓,即使在重合度接近0的情况下,F1依然能达到40%以上。这说明M-BERT可能具备了更深层次的表示能力,其跨语言迁移能力与“词表记忆”关系不大。
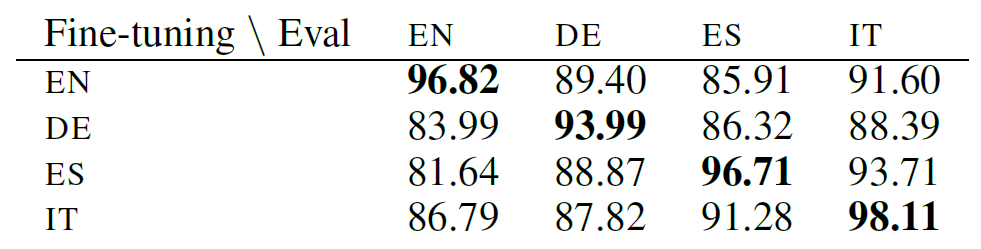
EN-BERT的跨语言泛化能力弱,会不会是因为英语词表的word piece表示其他语言数据的能力较弱呢?如果真的是这样,那么,就算我们使用其他语言微调EN-BERT,例如法语,然后在法语数据集上测试,得到的效果也会比较差。但事实并非如此,请看下表:

上表对比了EN-BERT和SOTA模型(实际上就是LSTM+CRF)在NER上的表现。训练(微调)和测试使用同一种语言,效果基本上平分秋色。这说明并不是EN-BERT对其他语言的表示能力差,而是缺乏跨语言表示能力,这种能力正是M-BERT所具备的。
为了证明M-BERT的跨语言泛化能力确实与“词表记忆”无关,再看一个更“极端”的实验:微调语言和测试语言拥有完全不同的字母表(script),因此它们的词表重合度为0。例如,Urdu(乌尔都语,使用阿拉伯字母表)和Hindi(印地语,使用天城文字母)词表重合度为0,英语、日语和保加利亚语的词表重合度为0。M-BERT的跨语言泛化能力再次令人惊讶:
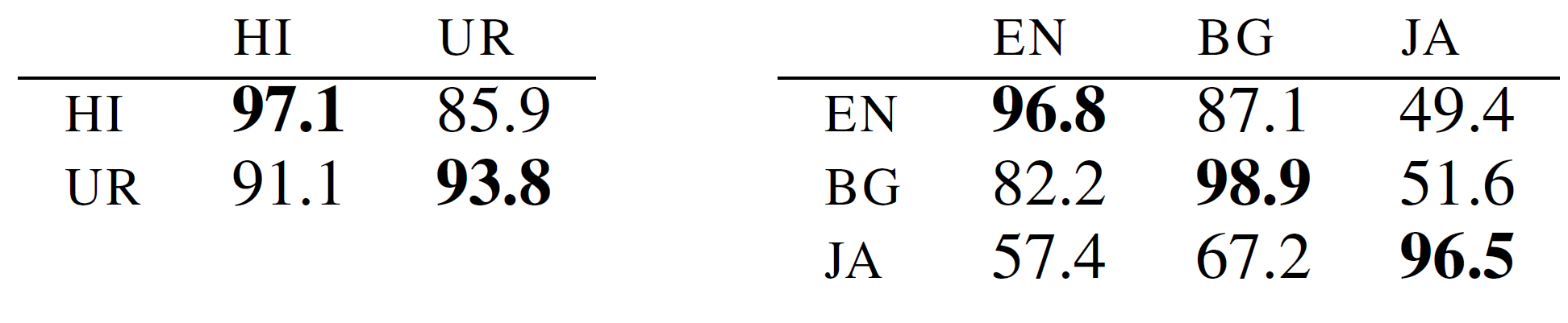
上表中,行表示微调语言,列表示测试语言。可以看出,即使使用完全不同的字母表,M-BERT在POS任务上的仍然取得了较高的准确率。这说明M-BERT能够基于用某单一语言训练得到的表示,把这种语言的结构映射到新语言的词表上。然而,再强的模型也有弱点。注意右表中的英语和日语,英语微调日语测试,或日语微调英语测试,准确率都不太高。可能的原因是,英语和日语的句子具有不同的主谓宾表达顺序,它们的语言类型相似性低,而英语和保加利亚语则具有相同的主谓宾顺序,它们的语言类型相似性高。这说明M-BERT在类型相似性较低的语言之间泛化能力较弱。
语言结构特征有较大影响
为了验证这一观点,论文从WALS(World Atlas of Language Structures,一个大规模语言结构特征数据集)选取了一个描述语法顺序的特征子集进行测试,这些特征包括主谓宾顺序、介词名词顺序、形容词名词顺序等。对于两种不同的语言,它们的共同WALS特征越多,两种语言类型越相似。在WALS特征子集上的测试结果如下:
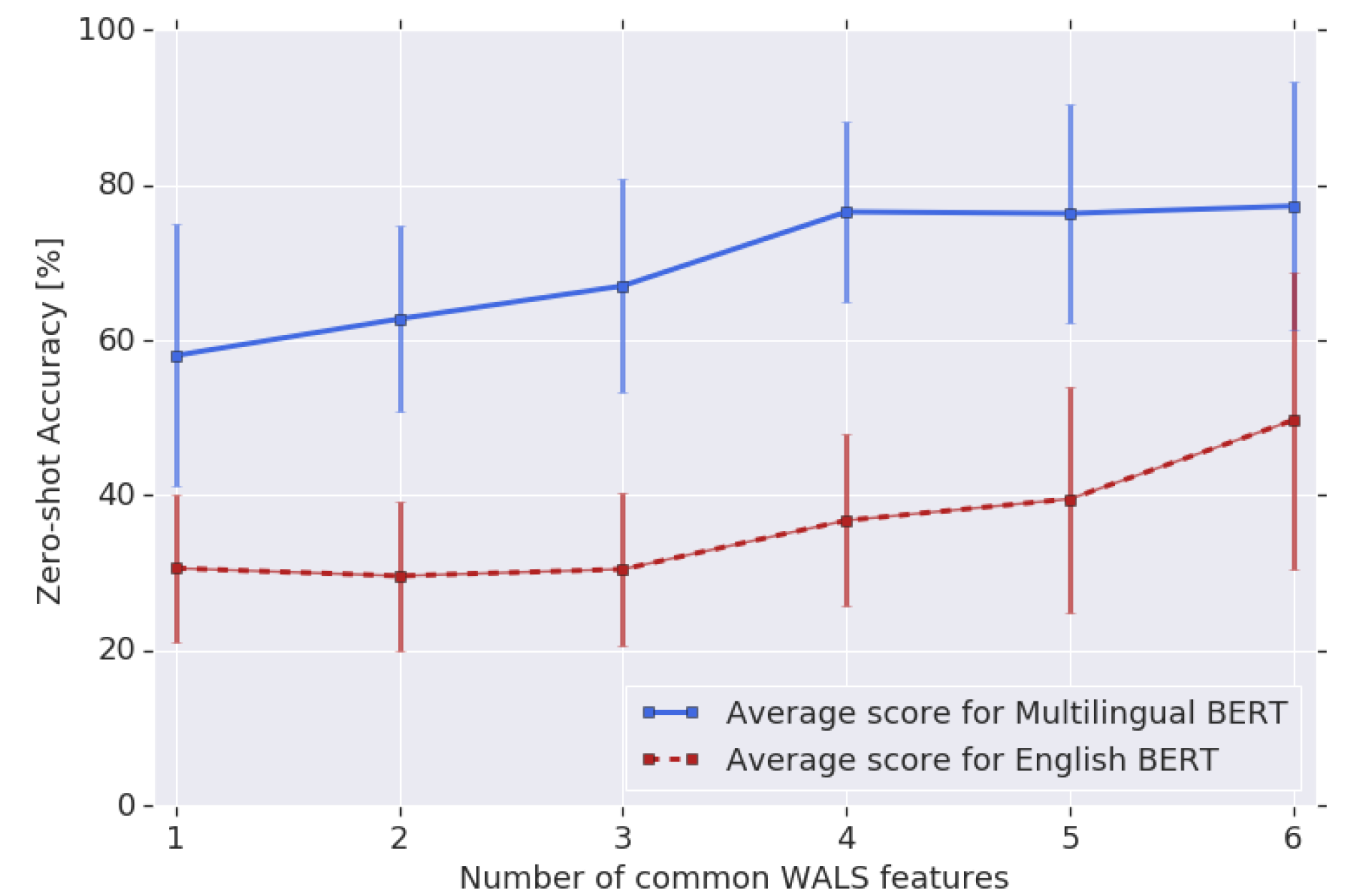
可见,两个语言的共同WALS特征越多,模型的跨语言泛化效果越好。即使两个语言只有一个共同特征,M-BERT的表现也比EN-BERT好。这说明:语言类型越相似,M-BERT映射语言结构越容易。
进一步探索两种结构特征“主谓宾顺序”和“形容词名词顺序”对M-BERT的影响。有些语言是“主谓宾”(SVO)结构,这些语言包括英语、法语、西班牙语、保加利亚语、意大利语等;有些语言则是“主宾谓”(SOV)结构,这些语言包括日语、韩语、土耳其语、印地语、乌尔都语等。下表展示了在POS任务上使用具有不同结构特征的语言微调和测试的宏平均准确率,行表示微调语言的结构特征,列表示测试语言的结构特征:
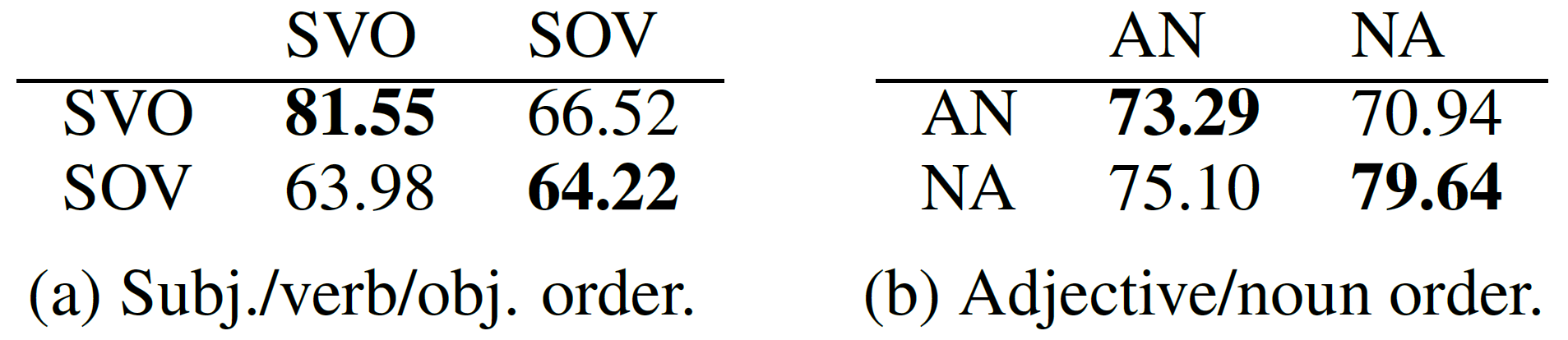
由左表可见,当微调语言和测试语言的主谓宾顺序一致时,M-BERT的表现最好,它似乎能把学到的语言结构映射到另一种语言的词表上。右表中形容词名词顺序也有类似的结果。
再来看一个更特殊的实验:使用语码转换语料微调M-BERT,并考察它的跨语言泛化能力。语码转换(code-switching)是指同一句子包含两种或更多语言。之前的实验都是仅使用一种语言微调,使模型获得了跨语言泛化能力。如果使用语码转换语料微调,模型还能跨语言泛化吗?
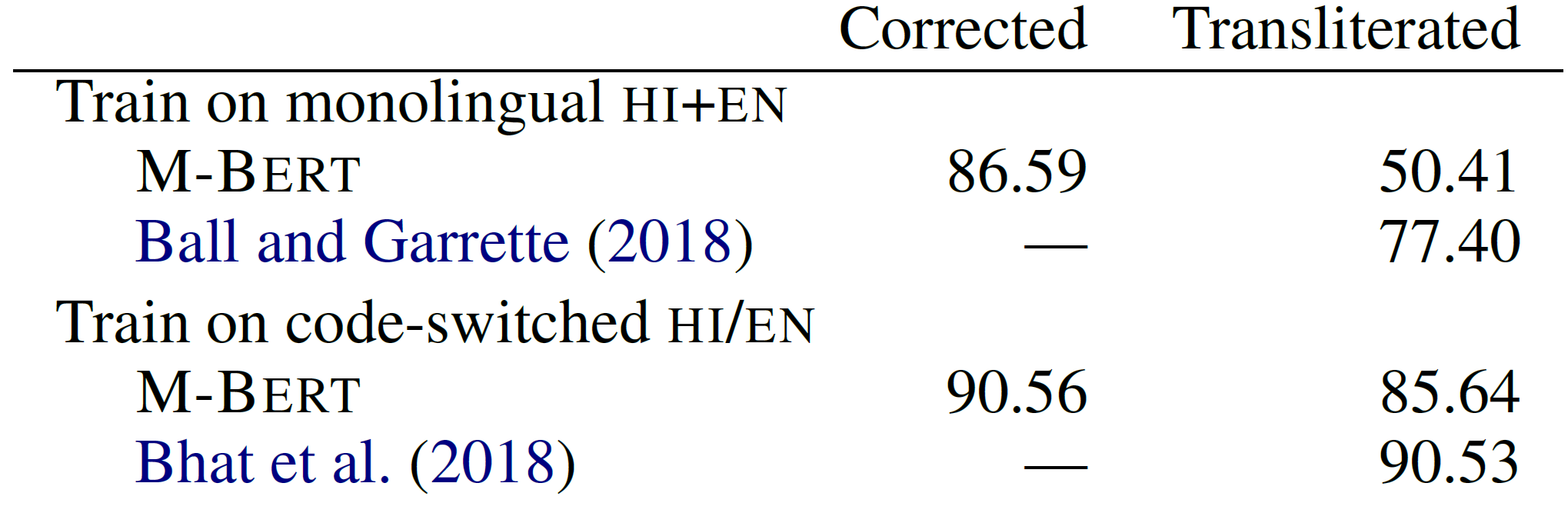
特殊的实验需要特殊的数据集,这篇论文提供了一个印地语-英语语码转换数据集。这个数据集提供了两种数据:一种在语码转换的基础上做了字母转写(transliteration),把印地语使用的天城文字母转换成了拉丁字母,另一种则是标注人员对字母转写语料做了字母修正(script-corrected)得到的语料,也就是把拉丁字母转换回天城文字母。同时使用这两种数据微调M-BERT,发现M-BERT在字母修正语料上做POS任务的效果较好,在字母转写语料上的效果较差。为了做对比,又同时使用印地语和英语两种单一语言数据微调M-BERT,同样发现模型在字母修正语料上的效果较好,在字母转写语料上的效果较差。具体情况如下图所示:
多语言共享特征空间
从WMT16数据集选5000个平行句子对,把它们分别输入M-BERT,无需微调,直接计算各层token向量均值(CLS和SEP两个token除外),作为该句子在各层的向量表示。例如,第\(i\)个平行句子对分别是英语和德语,英语句子在第\(l\)层的向量表示为\(v_{EN_{i}}^{(l)}\),德语句子在第\(l\)层的向量表示为\(v_{DE_{i}}^{(l)}\)。下面定义一个公式,用于把\(l\)层的英语句向量转换为德语句向量:
$$ \bar{v}^{(l)}_{EN\rightarrow ED}=\frac{1}{M}\sum_{i}\left (v^{(l)}_{DE_{i}}-v^{(l)}_{EN_{i}} \right ) $$
其中,M是句子对的数量。上式计算了\(l\)层所有从英语句向量指向德语向量的向量均值。要把\(l\)层的英语句向量 \(v^{(l)}_{EN_{i}}\)转为德语句向量,直接把它和\(\bar{v}^{(l)}_{EN\rightarrow ED}\)相加,然后搜索与计算得到的德语句向量最近的真实德语句向量,看看它是否和英文句子组成了正确的英德平行语料对,据此得到“最近邻准确率”,如下图所示:
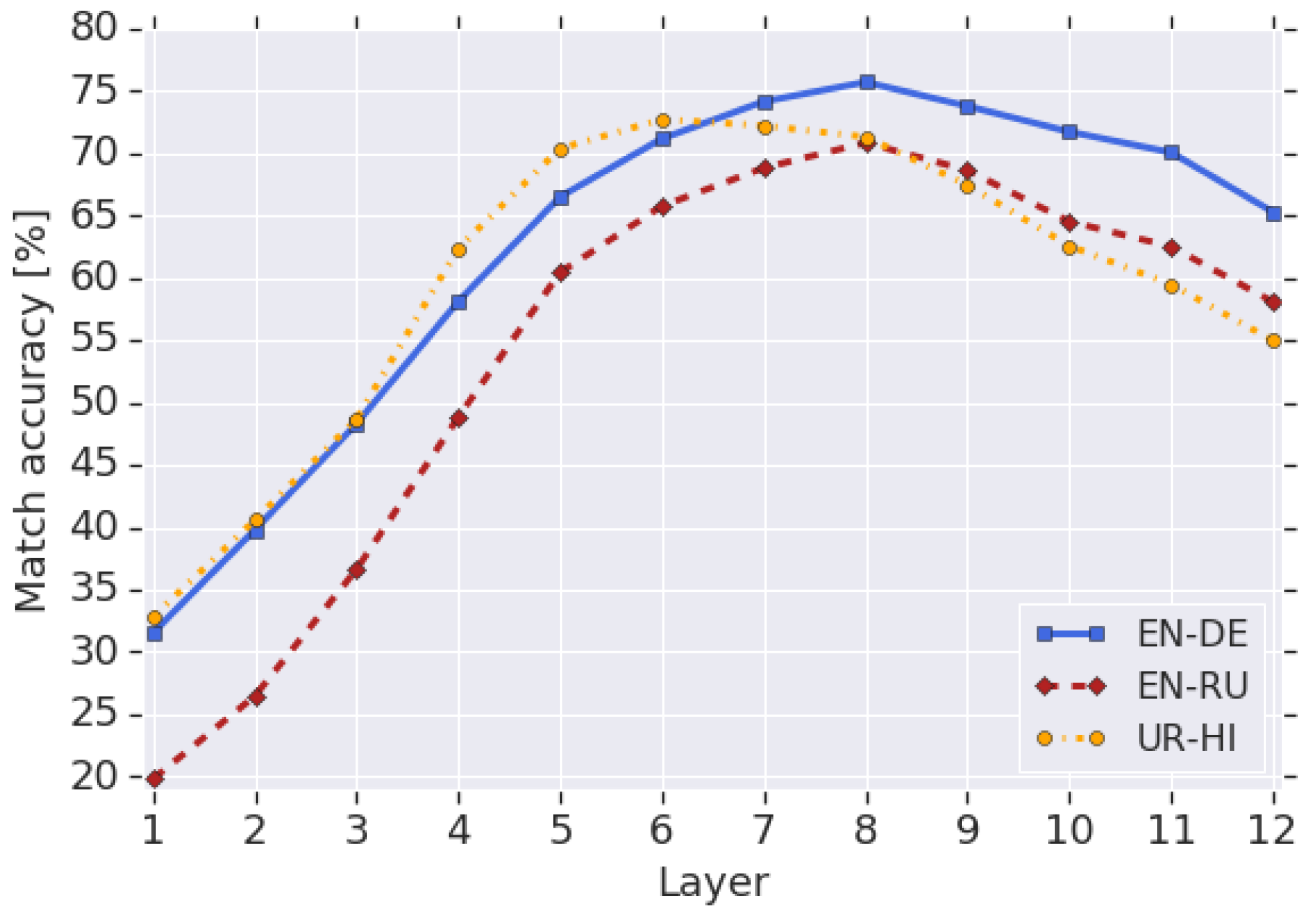
由上图可以看出,无论是英语-德语、英语-俄语,还是乌尔都语-印地语,从第5层往上的“最近邻准确率”都比较高。可见,从一种语言转换为另一种语言只需做简单的向量加减即可,说明这些语言共享了一个特征空间。较低层的“最近邻准确率”较低,可能是因为低层向量包含了更多的token信息,而不同语言的token差异较大,所以很难直接通过向量加减做转换。超过8层后,“最近邻准确率”也有所下降,可能是因为丢失了一些特定的语言信息。
写在最后
今日凌晨,克强总理去世,悲从中来。撰写此文直至次日凌晨,以缅怀这位心系民生的北大学长。
