大语言模型的参数高效微调:软提示
大模型 微调 随着模型规模越来越大,全量微调的成本越来越高,prompt方法的优势越发明显。无需更新模型参数,借助大模型的in-context learning能力,输入任务描述prompt,或者再加上一些样例,就能指导大模型完成下游任务。问题是如何构造prompt才能充分发挥大模型的威力?
最直接的方式是用自然语言构造prompt,人工编写一段文本输入大模型,这种prompt称为“硬提示(hard prompt)”或“离散提示(discrete prompt)”。但是,编写一段好的prompt需要花费较多精力,而且prompt的细微改动都可能影响模型表现:

上图是BERT-base-cased在LAMA-TREx P17数据集上的准确率,可以看出,即使只改变prompt中的一个单词,模型的表现也会迥然不同。
于是,“软提示(soft prompt)”出现了,也称为“连续提示(continuous prompt)”,prompt从一串离散的单词变成了连续的、可学习的向量,与原始输入文本的向量拼接起来作为新输入。prompt不再需要人工编写,在下游任务的数据集上微调模型时会更新prompt向量,最终学到合理的prompt表示。如果微调时冻结大模型参数,只更新prompt向量,需要更新的参数量极少,这样就实现了参数高效微调。
下面介绍两种软提示方法:p-tuning和prompt tuning。
P-tuning
2021年,GPT Understands, Too一文提出了p-tuning方法。初始化一个长度为m的虚拟prompt,\([P_{i}]\)是第\(i\)个虚拟token的向量表示。设原始输入文本为\(\mathbf{x}\),标签为\(\mathbf{y}\),m个虚拟token可以插入到\(\mathbf{x}\)和\(\mathbf{y}\)的不同位置,得到序列:
\[{[P_{0:i}], \mathbf{e(x)}, [P_{i+1:j}], \mathbf{e(y)}, [P_{j+1:m}]}\]那么,虚拟token之间有没有内在关联呢?很难说。p-tuning的做法是把虚拟prompt送进一个编码器\(f:[P_{i}]\rightarrow h_{i}\),以此建模虚拟token之间的依赖关系。于是,模型接收到的实际向量为:
\[{h_{0}, \dots, h_{i}, \mathbf{e(x)}, h_{i+1}, \dots, h_{j}, \mathbf{e(y)}, h_{j+1}, \dots, h_{m}}\]编码器通常是LSTM或MLP。下图展示了传统的离散提示和p-tuning的区别:
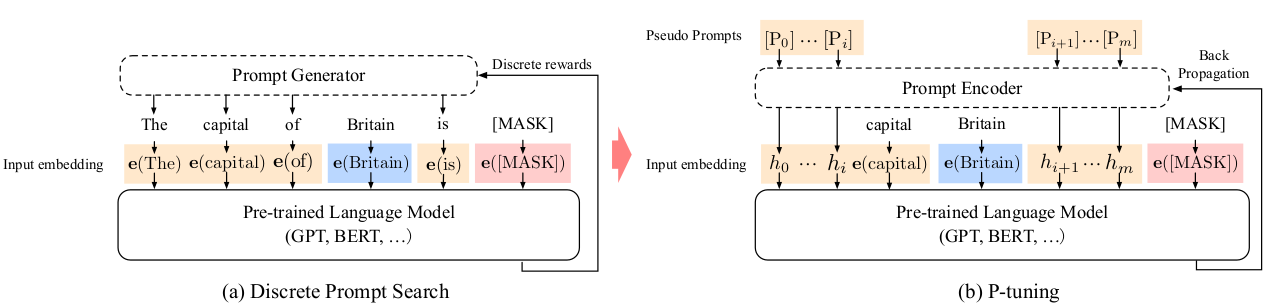
虚拟token的位置和数量对结果有影响吗?论文探讨了这个问题。以ALBERT在SuperGLUE的CB任务(自然语言推理)上的表现为例:

上表中,[P]表示虚拟token。对比1和3发现,如果[P]打断原始输入文本,效果会有下降。对比2和4发现,把[P]放在原始文本中间或前面,对效果没有影响。对比3、6、7、8发现,虚拟token的数量对效果有影响,过多的token会导致效果下降,原因可能是训练数据较少,虚拟token得不到充分学习更新。
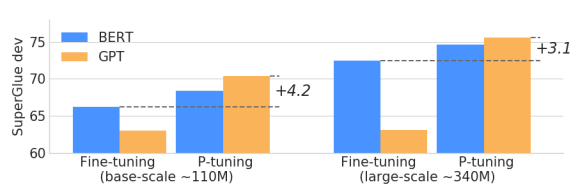
P-tuning显著提升了GPT在多个任务上的效果,使之可以与BERT抗衡,这也是论文题目的由来。从下图可以看出,模型规模越大,p-tuning的优势越明显:
Prompt tuning
同样是2021年,Brian Lester等人的论文提出了另一种软提示方法:prompt tuning。该方法与p-tuning类似,但更加简单。首先,它放弃了使用编码器建模虚拟token之间的依赖关系。其次,它只把虚拟token放在原始输入文本之前,不考虑其他位置。
例如,原始输入文本为\(\left\{x_{1}, x_{2}, \dots, x_{n}\right\}\),经过模型的嵌入层得到嵌入矩阵\(X_{e}\in\mathbb{R}^{n\times e}\),其中,e是嵌入向量的维度。设虚拟prompt的长度为p,初始化一个嵌入矩阵\(P_{e}\in\mathbb{R}^{p\times e}\)。把这两个矩阵拼在一起形成一个新矩阵\([P_{e};X_{e}]\in\mathbb{R}^{(p+n)\times e}\),这个矩阵才是模型的真正输入。微调时冻结原始模型的参数,只更新\(P_{e}\),实现参数高效微调。
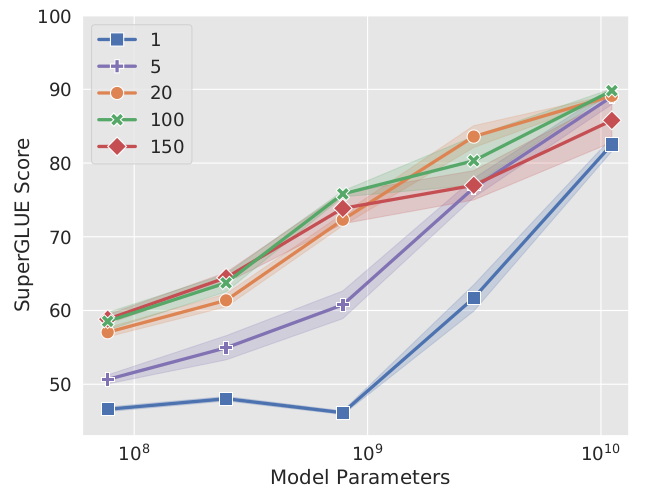
这篇论文也探索了虚拟token数量对模型效果的影响。从下图可以看出,对于大部分模型,虚拟token数量大于1是非常重要的。但是,对于参数规模达到百亿的大模型,即使只有一个虚拟token,也能得到较好的效果。
除此以外,论文还讨论了一些可能影响模型效果的因素,例如初始化prompt向量的方式。一种方式从[-0.5, 0.5]之间随机均匀采样,初始化embedding。另一种方式是从模型词表中选择5000个最常见的单词,从这个单词集合中采样,用单词embedding初始化prompt embedding。还有一种方法是下游任务的每个标签对应的单词embedding都用来初始化一个虚拟token,如果prompt较长,标签数量不够用,就按照第二种方法,从词表中随机采样一些单词,初始化剩余的虚拟token。
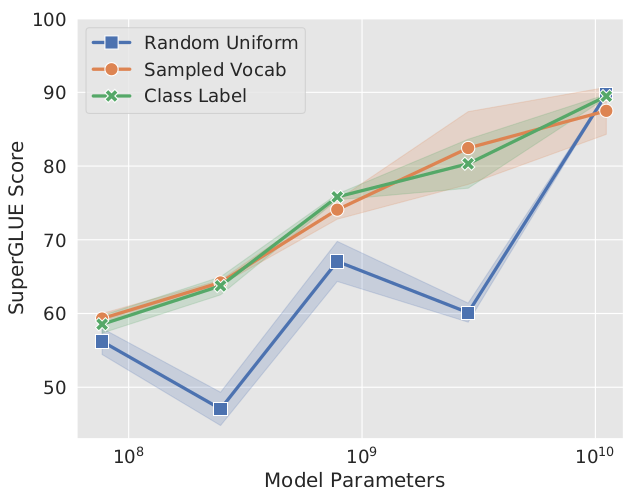
当模型规模较小时,后两种方法优于随机初始化。但是,当参数规模达到百亿,这些初始化方法的效果基本相同。
源码对比
为了更好地理解p-tuning和promp tuning,我们直接阅读Huggingface PEFT实现这两种方法的源码。首先看p-tuning实现编码虚拟prompt的代码:
def forward(self, indices):
input_embeds = self.embedding(indices)
if self.encoder_type == PromptEncoderReparameterizationType.LSTM:
output_embeds = self.mlp_head(self.lstm_head(input_embeds)[0])
elif self.encoder_type == PromptEncoderReparameterizationType.MLP:
output_embeds = self.mlp_head(input_embeds)
else:
raise ValueError("Prompt encoder type not recognized. Please use one of MLP (recommended) or LSTM.")
return output_embeds
再看prompt tuning实现编码虚拟prompt的代码:
def forward(self, indices):
# Just get embeddings
prompt_embeddings = self.embedding(indices)
return prompt_embeddings
上面两个函数中,输入indices都是虚拟token的ID序列,self.embedding是虚拟token的嵌入查找表,在各自的__init__函数中初始化。不同之处在于,prompt tuning直接返回查到的embedding,p-tuning返回的则是用LSTM或MLP编码器对查到的embedding做变换之后的结果。
在p-tuning和prompt tuning的__init__函数中都有下面一行:
self.embedding = torch.nn.Embedding(self.total_virtual_tokens, self.token_dim)
但是,prompt tuning还可以使用文本初始化,也就是上文介绍的从模型词表中采样一些单词并用这些单词的embedding初始化虚拟token向量。因此,prompt tuning的__init__函数中还有如下代码:
if config.prompt_tuning_init == PromptTuningInit.TEXT and not config.inference_mode:
from transformers import AutoTokenizer
tokenizer_kwargs = config.tokenizer_kwargs or {}
tokenizer = AutoTokenizer.from_pretrained(config.tokenizer_name_or_path, **tokenizer_kwargs)
init_text = config.prompt_tuning_init_text
init_token_ids = tokenizer(init_text)["input_ids"]
# Trim or iterate until num_text_tokens matches total_virtual_tokens
num_text_tokens = len(init_token_ids)
if num_text_tokens > total_virtual_tokens:
init_token_ids = init_token_ids[:total_virtual_tokens]
elif num_text_tokens < total_virtual_tokens:
num_reps = math.ceil(total_virtual_tokens / num_text_tokens)
init_token_ids = init_token_ids * num_reps
init_token_ids = init_token_ids[:total_virtual_tokens]
init_token_ids = torch.LongTensor(init_token_ids).to(word_embeddings.weight.device)
with gather_params_ctx(word_embeddings):
word_embedding_weights = word_embeddings(init_token_ids).detach().clone()
word_embedding_weights = word_embedding_weights.to(torch.float32)
self.embedding.weight = torch.nn.Parameter(word_embedding_weights)
无论是p-tuning还是prompt tuning,最终都在peft_model模块中调用。以该模块的PeftModelForSequenceClassification为例,在它的forward函数中有如下代码:
prompts = self.get_prompt(batch_size=batch_size, task_ids=task_ids) # 获得虚拟prompt embedding
prompts = prompts.to(inputs_embeds.dtype)
inputs_embeds = torch.cat((prompts, inputs_embeds), dim=1) # 拼接prompt和真正输入的embedding
在Huggingface PEFT的实现中,p-tuning和prompt tuning拼接prompt和输入的方法是一样的,都是把prompt放在输入前面,并未体现p-tuning中提到的把prompt放在输入的其他位置。
除上面两种方法外,软提示还有其他形式,如prefix-tuning和p-tuning v2等,与上述两种方法均有类似之处,另写一篇文章介绍。