简明GLM
transformers glm 讲解GLM的文章已有不计其数,很多人喜欢从描述训练任务和目标函数讲起。这里,我直接从论文给出的示意图开始,看图说话,可能更直观。
预训练
设输入GLM的token序列为\(\mathbf{x}=\left[x_1,\cdots ,x_n\right]\),如下图a所示。
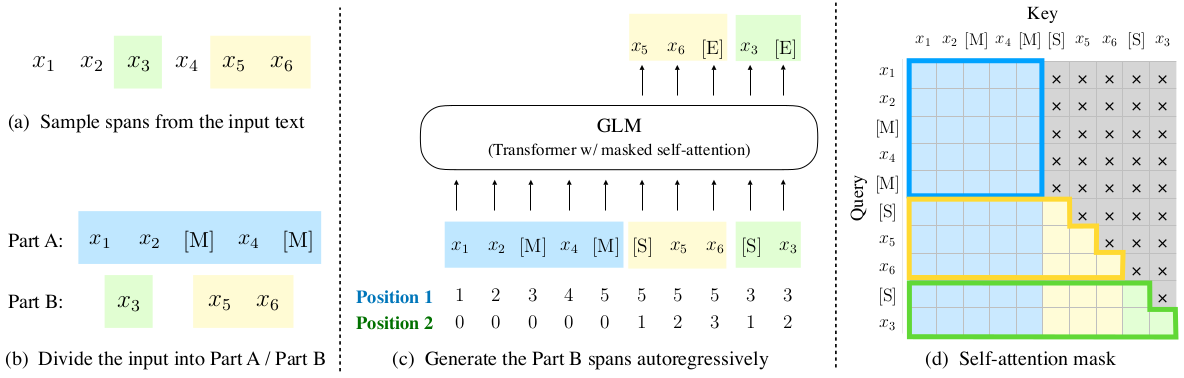
预训练任务主要分两步:
-
GLM从该序列中随机挑选一些片段并用[MASK]替换它们。例如,把片段\([x_3], [x_5, x_6]\)替换为[MASK]后,得到A、B两部分文本,如上图b所示。片段长度从\(\lambda=3\)的泊松分布中采样得到。采样,替换,如此往复,直到被替换的token数量达到总数的15%时停止。
-
把A、B两部分拼在一起,让GLM预测每个被[MASK]替换的片段。为了隔开输入片段,在每个输入片段的前面加上[START]。同样地,为了隔开输出片段,在每个输出片段的后面加上[END]。GLM根据A,以自回归的方式生成B中的每个片段。例如,在上图c中,根据\([x_1, x_2, [MASK], x_4, [MASK]]\)预测片段\([x_5, x_6, [END]]\),然后根据\([x_1, x_2, [MASK], x_4, [MASK], [START], x_5, x_6]\)预测片段\([x_3, [END]]\)。
为了实现自回归地生成B中的片段,需要对常规的双向self-attention做些调整:预测当前位置的token时,应该像Transformer decoder一样,让模型看不到当前位置之后的内容。如图d所示,GLM的self-attention对A和B两部分区别对待:A部分使用双向self-attention,B部分使用单向self-attention。
至此,预训练的要点介绍完毕,下面再说几个细节。
2D位置编码
名字起得比较唬人,实际上就是同时使用两套位置编码,如图b所示。第一个位置编码描述token在A中的绝对位置,具体做法是给A部分的每个token和[MASK]都赋一个位置编码,给B部分每个片段的token都赋一个与A部分对应[MASK]相同的位置编码。第二个位置编码描述B部分token在片段中的绝对位置,A部分的位置编码都为0。
多任务目标函数
设采样得到的m个片段为\(\left\{\mathbf{s_1}, \cdots, \mathbf{s_m}\right\}\),用它们组成B部分。注意,为了学习不同片段之间的依赖性,GLM会打乱这些片段的排列顺序(但不打乱每个片段内部的token顺序),对每种排列都做预测。(说实话,这个操作很让我费解,打乱片段顺序就能让模型学到片段时间的依赖关系?如果打乱顺序就有效果,何不打乱token顺序,让模型学到token之间的依赖关系?)记A部分为\(\mathbf{x}_{corrupt}\),m个片段的全排列集合为\(Z_m\),则自回归生成片段的目标函数可以表示为:
\[\max_{\theta}\mathbb{E}_{\mathbf{z}\sim Z_{m}}\left[\sum\limits_{i=1}^{m}\log p_{\theta}(\mathbf{s}_{z_i}\mid \mathbf{x}_{corrupt}, \mathbf{s}_{\mathbf{z}_{<i}})\right]\]其中,\(\mathbf{s}_{z_i}\)表示排列\(\mathbf{z}\)中的第\(i\)个片段。可见,这个目标函数优化的是所有排列的自回归最大似然之和。
然而,上面介绍的片段采样方法和目标函数适合自然语言理解任务,却不适合文本生成任务。因为自然语言理解(例如文本分类)可以转化为短文本生成任务(例如直接生成标签),而上面采样的片段大都是短文本,所以GLM只学到了生成短文本的能力。
为了生成长文本,需要遮盖更长的片段。于是,GLM设计了两种新的片段采样方法:
- 篇章级采样:按照均匀分布,采样一个长度为原文的50%-100%的片段。这种采样方式能让模型学到生成长文本的能力。
- 句子级采样:采样若干句子,句子的token数量占原文15%以上。这种采样方式能让模型学到seq2seq的生成能力,例如补全句子等。
把这两个采样方法和上面的目标函数结合,再加上原有的片段采样方法对应的目标函数,就构成了GLM的多任务目标函数。
微调
对于自然语言理解任务,微调时通常可以先让模型编码输入文本,然后加上一层全连接网络适配做分类任务。但是,这样的微调方式与文本生成任务不同,GLM希望用一种统一的方式微调模型,即把自然语言理解任务转化为文本生成任务。
以情感分类为例,假设有一个样本,文本是Coronet has the best lines of all day cruisers,标签是Positive。训练时,输入模型的实际文本是Coronet has the best lines of all day cruisers. It is really [MASK],标签经过verbalizer转化为更像自然语言的good。于是,GLM的任务是根据输入文本,恢复被[MASK]遮盖的good,如下图所示:
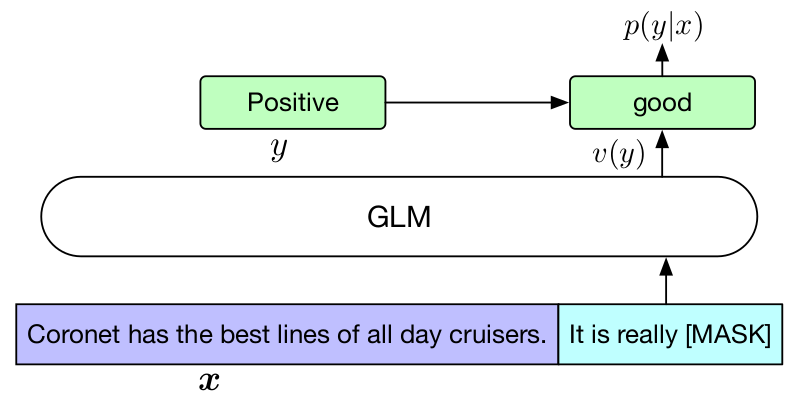
对于文本生成任务,微调GLM时,在输入文本最后加上[MASK]作为A部分,然后自回归生成B部分。
GLM介绍完了。虽然有些设计我感觉很扯淡,但也有一些有趣的思路,比如用自回归的方式生成片段,再比如为不同的任务设计不同的采样方式,形成多任务目标函数等。
可以说,是大模型让GLM火起来,如果没有ChatGPT引爆的大模型热潮,GLM可能就被埋没在众多的文本生成模型中了。有道是“时来天地皆同力,运去英雄不自由”,然也!