聊聊国内银行的大模型
大模型 最近配合同事准备一份汇报材料,调研其他银行的大模型研发和应用情况。在网上看了工行、建行、交行、招行、兴业关于大模型的公开报道,可以说乏善可陈。其中,工行、兴业和招行在大模型研发领域做了些工作,其他银行鲜有提及自研,场景介绍大多也很空洞,出彩的探索很少。
忽然想起ChatGPT火爆之初,招行一马当先,号称业内首次把大模型用在银行场景。本以为是什么了不起的创新,结果就是发布了一张信用卡,卡面文案用大模型生成。虽然有点好笑,也能看出虽然银行对大模型持开放欢迎态度,但并没想好如何让大模型赋能场景。
试探性繁荣
今年4月份,钛媒体有篇报道,从各大银行2023年报中整理出来关于大模型的信息。如下图所示:
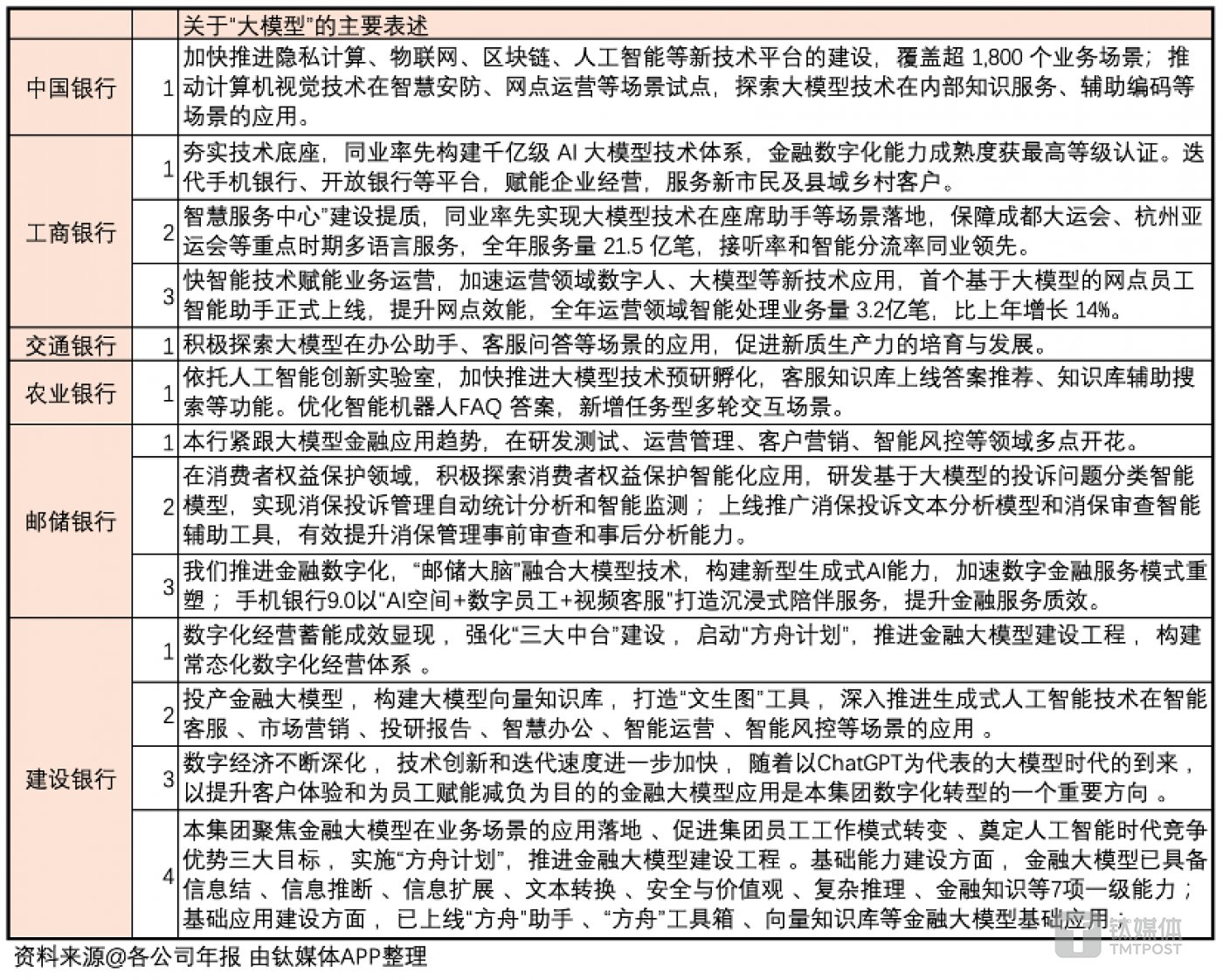
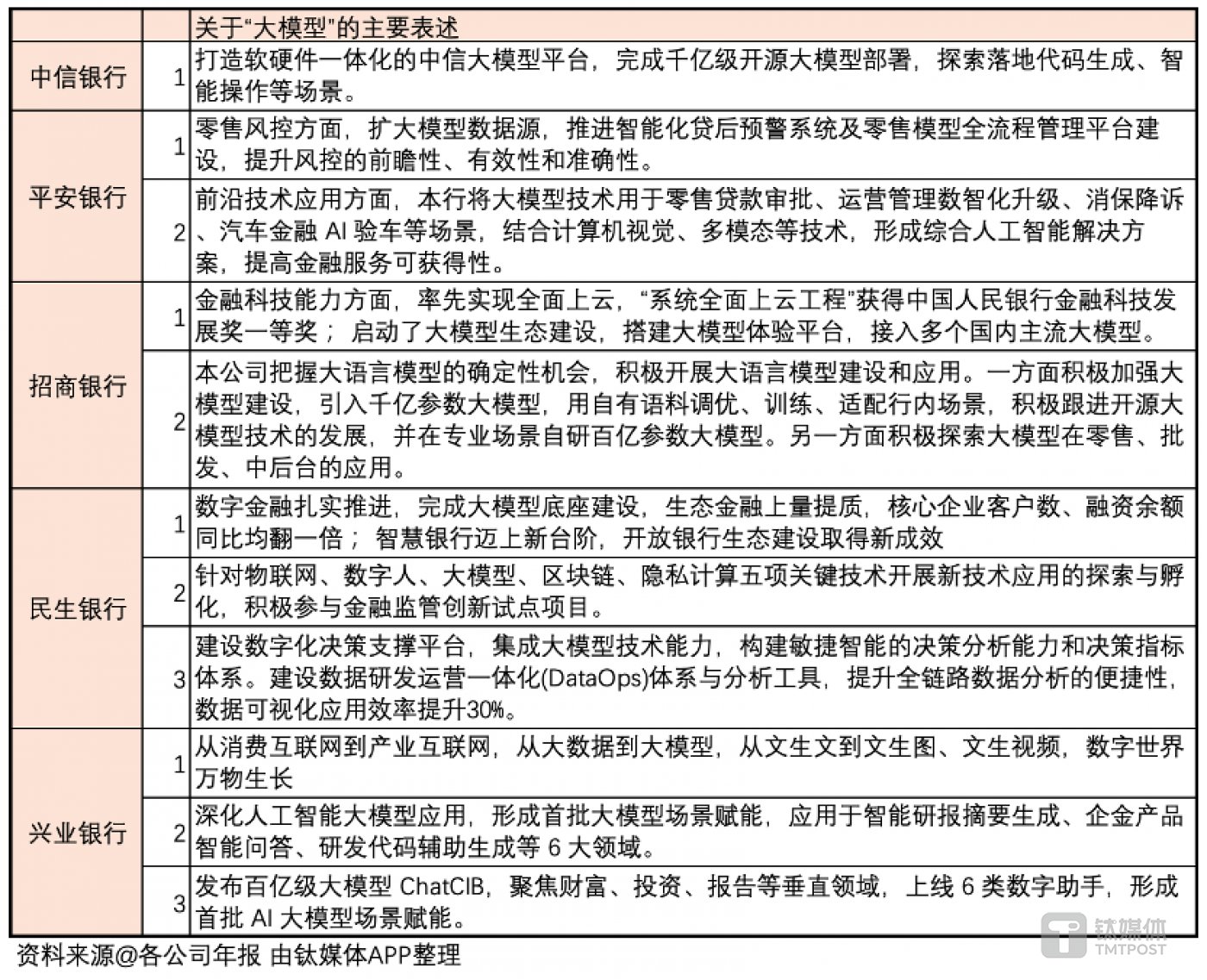
银行在哪些场景使用大模型?从上面两张图可管窥一二:
- 中国银行:内部知识服务,辅助编码
- 工商银行:座席助手,网点员工智能助手
- 交通银行:办公助手,客服问答
- 农业银行:客服知识库答案推荐,知识库辅助搜索
- 邮储银行:研发测试,运营管理,客户营销,智能风控,投诉问题分类
- 建设银行:向量知识库,文生图,智能客服,市场营销,投研报告,智慧办公,智能运营,智能风控
- 中信银行:代码生成,智能操作
- 平安银行:零售贷款审批,运营管理,消保降诉,汽车金融AI验车
- 招商银行:零售,批发,中后台
- 民生银行:数字化决策
- 兴业银行:智能研报摘要生成,企金产品智能问答,研发代码辅助生成,数字助手
上图中,工行、平安和兴业的落地场景最为具体。工行和平安堪称是国有行和股份制行中的金融科技领导者,所以这两家银行能找到清晰的场景并不意外。招行的科技研发实力很强,但从上图中没看到特别出彩的大模型应用。兴业能快速落地这么多场景,有点出乎意料,由此推测也在加大科技投入。
六大国有行中,工行提到了大模型自研。所谓“率先构建千亿级AI大模型技术体系”,从另一篇报道来看,应该是和鹏城实验室、清华、中科院、华为一起研发了千亿参数大模型,基于昇腾AI,而且在多个场景落地:
目前,工商银行金融行业通用模型已被创新应用于客户服务、风险防控、运营管理等多个业务领域,取得了良好的应用效果。在客户服务领域,工商银行应用该模型支撑智能客服接听客户来电,显著提升了对客户来电诉求和情绪的识别准确率,能够更精准有效地响应客户需求,并且可以大幅缩减维护成本。在风险防控领域,工商银行实现了对工业工程融资项目建设的进度监测,监测精准度提升约10%,研发周期缩短约60%。在运营管理领域,模型的应用帮助智能提取期限、利率等信贷审批书核心要素,提升了信贷审批效率。
然而,客户来电诉求和情绪识别未必需要大模型,训练好的小模型即可做出又快又准的判断;进度监测不知为何物,不做评论;从审批书中提取核心要素,在无标注数据的情况下,使用大模型较为妥当。按照我的经验,多方参与大模型研发,银行一般是甲方角色,出场景出资金,但是技术贡献度很低。不管怎样,工行敢吃螃蟹,这一点值得表扬。
其他国有行也没闲着。农行2023年3月发布ChatABC(我猜测可能不是ChatGPT那样的大模型,因为Llama的第一版参数2023年3月初才被人泄露到网上,强如Bloomberg,他们的GPT也是到2023年3月底才发布),建行启动“方舟计划”,邮储今年5月份和智谱签署战略合作协议,都在疯狂试探大模型。
再看股份制银行,兴业提到“发布百亿级大模型ChatCIB”,疑似自研。网上关于该模型的信息很少,官网上也只是简单提及:
近年来,兴业银行全面加快数字化转型,深化人工智能大模型应用,上线百亿级大模型ChatCIB,聚焦量化投研、营销财富、知识问答、报告生成、办公辅助、代码服务领域打造6类数字助手,形成首批AI大模型应用,为推进高质量发展注入新活力。
除此以外,我找到了兴业银行的另一个大模型:随兴写,用于反洗钱场景。从这篇报道看,应该是兴业自主研发的:
“随兴写”是基于兴业银行自主研发的可疑交易报告智能生成模型(AML-GPT),利用大模型与自然语言处理技术,智能分析洗钱可疑客户行为、可疑主体信息和可疑交易信息等特征,并生成可疑交易辅助分析报告,并通过运用智能问答技术,甄别人员可在模型生成的初稿基础上快速调整优化,实现兴业银行类GPT大模型从0到1的突破
“在没有智能辅助工具的情况下,我们每天需要处理约30份可疑交易报告,每份报告都需要经历开展调查、分析交易流水与行为特征到撰写报告的过程,每份报告处理时长20-60分钟不等。”分行一位基层反洗钱员工表示。
“随兴写”利用强人工智能技术,训练反洗钱可疑案宗报告智能生成模型,依托于系统涵盖的多维度特征,综合分析研判形成符合反洗钱专家逻辑的可疑分析报告,并给出初步处理意见
这篇报道发表于7月底,比上面的表格晚了3个月。可见,ChatCIB可能不是兴业自研大模型。ALT-GPT是如何训练的呢?我猜测是基于某个开源大模型,用兴业积累的大量可疑交易报告和行为特征微调,例如,输入行为特征,输出可疑报告。难度也许不大,但是想法独特,好像从没有银行专门研发反洗钱大模型,值得表扬。
招行也提到了“在专业场景自研百亿参数大模型”,具体情况没有找到,猜测是基于llama微调的。另外看到了这篇报道:
智谱AI的千亿基座模型GLM-130B成为此次合作的核心驱动力,配合招商银行自主研发的百亿参数级大模型,共同在零售、批发及中后台等多个业务领域实现了智能化升级,如智能财富顾问、数字产品管理等应用的成功落地。
看来不仅有自研大模型,也从厂商采购了大模型。不知道招行对GLM评价如何,曾经看过GLM的论文,可能是为了兼顾NLU和NLG,预训练任务设计十分奇怪,多任务之间颇有些自相矛盾。我的经验是,想要模型两头都占,恐怕哪头都占不着。当然,在大力出奇迹的年代,一切皆有可能,最新GLM4不知道是否有改变。
另外值得一提的是平安银行,上图中好像没有提及自研大模型,这并不奇怪,因为平安银行的许多技术方案来自平安科技,这是众所周知的。平安入局大模型较早(我记得2023年开年就从上到下把人马组织起来了),而且一些保险和医疗场景已经在用自研的PingAnGPT。从这篇报道可以了解到平安银行自研了BankGPT:
针对L2场景大模型,基于BankGPT训练的专业理财大模型,反馈结果比较匹配。它首先会判断客户意图,评估客户对长期理财是否感兴趣,是否愿意参加相关的营销活动。其次,从策略角度讲,针对需要推荐的产品,自动化生成话术,同时会推荐其他的业务产品,在客户服务过程中,以消息方式推送给客户经理进行推荐提醒和辅助
通过描述猜测BankGPT是大模型训练工具或平台,也可能具备接入、推理等功能,方便大模型应用,而非大模型本身。平安银行有没有用上自研GPT目前不得而知,但是我猜早晚会用的。
场景为王
总体上看,各大银行都进入大模型军备竞赛,争先恐后,或采购,或自研。但是,出彩的场景并不多,而且所谓自研,大概就是基于某个开源模型用场景数据微调。这无可厚非,毕竟银行是需要极度安全、极度可靠的服务,大模型目前为止还是黑盒,限制了它在严肃场景中的使用范围。而且银行数据不外流,行内资源又极其有限,大模型应用困难重重。
从技术角度看,大模型的核心能力是“生成”,围绕这个核心开发业务场景胜算才会更高,例如代码辅助、知识问答等。一个非常实用的场景是用大模型辅助标注,用于训练更精准的小模型。最近一两年,每家银行都把“降本增效”挂在嘴边。用同等能力的小模型替代大模型,就是一种降本增效的好方法。
从银行业的特点看,银行的服务属性与大模型的强大交互能力天然契合。假以时日,大模型在银行业必然开花结果。以我个人经验来看,场景远不止上图提及的那些,可能还有些“出力不讨好”的偏门场景,反而是大模型的用武之地。从银行内场景起步,逐步发展到对客场景,也不是不可能。
但是,万事都怕过火。与其滥用,不如不用,更何况当前大模型能力远没有达到让人放心的程度。如果场景可以使用小模型解决,就没有必要投产大模型。然而,银行技术力量相对薄弱,有时不知道什么场景该用什么模型。这时特别需要“懂行”的专家合理评估,最大限度发挥各种模型的特长,而不是死磕大模型。不管大模型小模型,能解决问题的就是好模型。