LLaMA3是怎样炼成的-基座篇
llama 大模型 天下难事必作于易,天下大事必作于细。是以圣人终不为大,故能成其大。 – 《道德经》
LLaMA3的训练过程主要分为预训练(pre-training)和后训练(post-training)两个阶段。本文主要关注前者,通俗地说,就是如何训练“基座”。
官方论文介绍,预训练LLaMA3 405B使用了Meta生产集群上的16K个H100,耗时54天,任务经历47次计划内中断,419次意外中断(大部分是硬件问题),最终修炼出比肩GPT4的强大能力。
论文长达92页,训练过程的方方面面都点到了。但是,我认为关于预训练最核心的一句话是:
It does not deviate significantly from Llama and Llama 2 in terms of model architecture; our performance gains are primarily driven by improvements in data quality and diversity as well as by increased training scale.
这句话点明了大模型“涨点”的关键因素:数据质量和多样性,以及更大的训练规模。下面我们从训练数据、模型结构和模型规模三方面介绍LLaMA3是怎样炼成的。
炼数据
正所谓“天下大事必作于细”,耐不住萃取数据的枯燥乏味,就炼不出睥睨群雄的大模型。为了得到高质量训练数据,LLaMA3主要做了三件事:
- 数据治理(Data Curation)
- 数据混合(Data Mix)
- 数据退火(Annealing Data)
数据治理
LLaMA3使用的网络数据截止到2023年底,来源五花八门,所以必须对数据做去重、过滤等操作。具体有以下几个方面:
- 过滤
- 定制过滤器:去除敏感和有害信息,例如PII和成人内容;
- 启发式策略
- 计算重复n-gram覆盖率过滤日志内容
- 统计dirty word过滤成人内容
- 计算token分布的KL散度过滤包含过多outlier token的内容
- 过滤低质量文档
- 用fastText预测文档是否会被为维基百科引用
- 用LLaMA2辅助标注文档是否符合质量要求,然后训练DistilRoBERTa输出质量分数
- 文本提取和清洗
- 定制HTML解析器
- 保留图片alt属性
- 移除markdown标记
- 去重
- URL级:只保留日期最近的URL文档
- 文档级:计算MinHash,去除特别接近的文档
- 行级:每个桶包含30M文档,去除每个桶中重复6次以上的行
此外,对于代码和推理数据,先用微调过的LLaMA2辅助标注训练数据,然后训练DistilRoberta分类器,判断网页内容是否为代码或推理数据,最后用特定HTML提取器完成任务。对于多语种数据,先用fastText判断文档语种,然后用前面介绍的方法做提取、清洗、去重等操作。
LLaMA3数据处理过程堪称大小模型合作典范,没有小模型精准筛选语料,大模型就无法获得干净的训练数据。所以,你大可不必为小模型在大模型时代还有没有用武之地感到焦虑。善用小模型,才能得到优质大模型。
数据混合
训练LLaMA3需要混合不同内容的数据,以确保数据多样性。那么,数据配比秘方怎么来的?主要靠两大法宝:一是知识分类,二是scaling laws。
通过训练知识分类器,判断每个网页的内容类别,可以调控不同类别的内容在训练数据中的比例。例如,网上充斥了大量的娱乐信息,所以要对语料中的娱乐内容做下采样。
用不同内容配比的训练数据训练一些规模较小的模型看效果,然后利用scaling laws预测规模较大的模型在这些配比策略上的性能,最后选出一个最佳配比训练大模型。
按照token数量统计,最终配方是:50%通用知识,25%数学推理,17%代码,8%多语种。
数据退火
退火(annealing),原本是一种把金属加热到一定温度然后缓慢冷却的工艺。做AI的人总能整出些新花样,例如Pytorch中有一种控制学习率衰减的策略,就叫CosineAnnealing。
这里的“退火”,是指训练到最后40M token的时候,把学习率线性衰减到0,同时调整数据混合配比,上采样高质量的特定领域数据,例如,想要提升模型的代码和推理能力,就上采样代码和数学推理数据。最后用退火过程中的平均checkpoint作为最终的预训练模型。
这个招数非常有效,据说让LLaMA3 8B在GSM8k和MATH数据集上的性能分别提升24%和6.4%。但是对405B效果不明显,可能是因为405B已经具备极强的推理能力,不再需要这种奇技淫巧了。
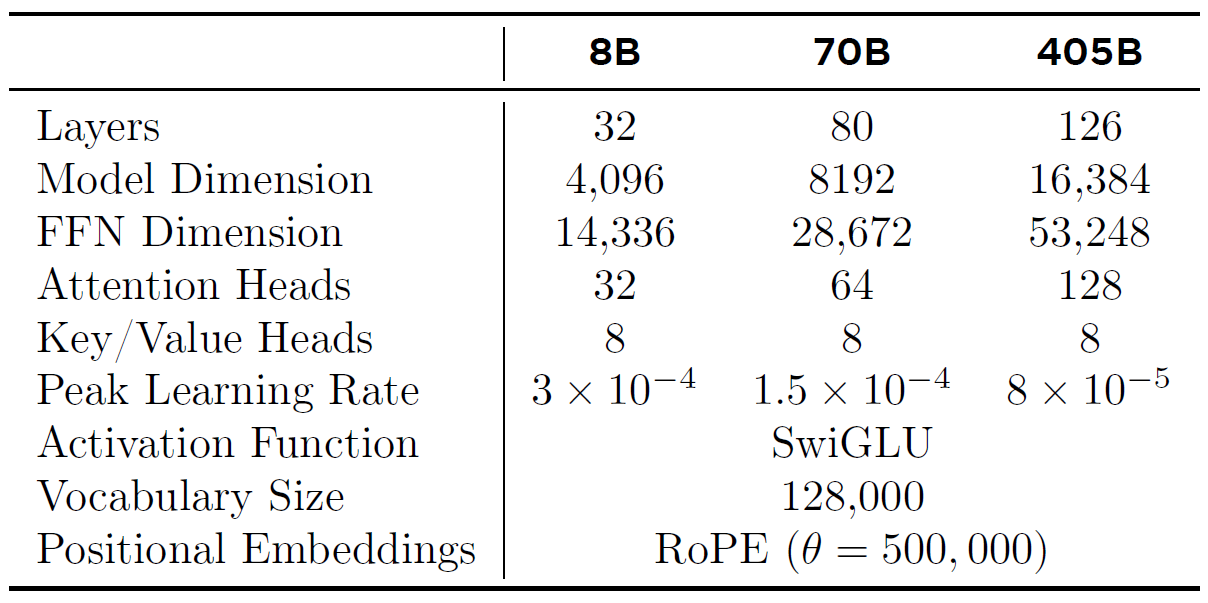
练结构
LLaMA3的强大能力不靠魔改网络结构,所以论文轻描淡写。相比LLaMA1和2,虽说LLaMA3的模型结构没有太大变化,但还是有些许调整,直接看下图:
炼规模
Scaling law的核心目标是在限制compute budget(通常用FLOPs衡量)的情况下找到模型参数量和训练数据量(通常用token数衡量)的最佳组合,使模型loss最低。
LLaMA3的一个重要创新点是扩展了scaling law,直接根据FLOPs预测模型在下游任务上的表现。换句话说,只要给出compute budge,不用训练模型,就只道模型能达到什么效果,堪称未卜先知。
要得到这个超能力,主要分两步:首先建立FLOPs和模型负对数似然loss之间的关系,然后建立loss和下游任务效果之间的关系。
先来看看怎样实现第一步。
LLaMA3实验了compute budget从$6\times 10^{18}$到$10^{22}$ FLOPs,实验模型参数量从40M到16B,得到不同budget下token数和验证集loss的关系:
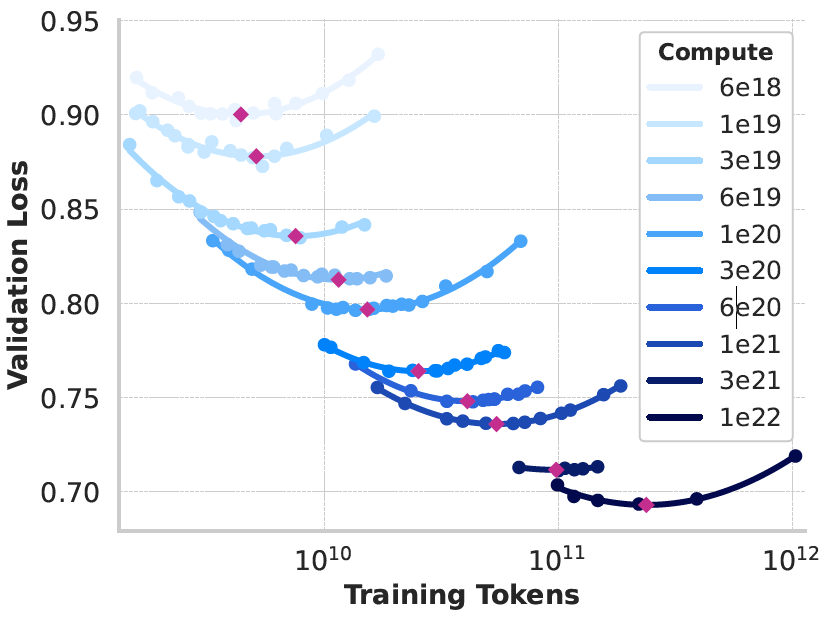
上图中的每条曲线都是抛物线,LLaMA3用每条抛物线最小值(上图中的红点,对应的模型称为compute-optimal模型)拟合budget和token数之间的关系,得到如下公式:
\[N^{*}(C)=AC^{\alpha}\]其中,A=0.299,\(\alpha=0.537\),C是budget,\(N^{*}(C)\)是token数。如果把\(C=3.8\times 10^{25}\)FLOPs代入公式,得到训练token数大约是16.55T。对应的模型参数量是多大呢?
理论上,根据经典公式
\[C\approx 6\times 模型参数量 \times 训练token数\]可以估算出最佳的模型参数量约为389B,论文给出的参数量为402B,与我们估算出的处于同一数量级(实际相差10B以上,所以这里只是估算)。
另外,从上图还能观察到一个现象:compute budget越大,抛物线的曲率越小。这说明当budget足够大时,模型参数量和token数之间的权衡不会对模型性能产生较大影响。所以,LLaMA3把参数量从402B调整到了405B。
至此,LLaMA3已经构建出FLOPs和loss之间的关系。接下来看看如何实现第二步,即建立loss和下游任务效果之间的关系。
以ARC Challenge benchmark为例。首先基于上面提到的scaling law实验模型建立FLOPs和loss之间的关系,这里的FLOPs最大为\(10^{22}\),得到下面的左图。然后基于scaling law实验模型和LLaMA2建立loss和准确率之间的sigmoid函数关系,得到下面的右图。
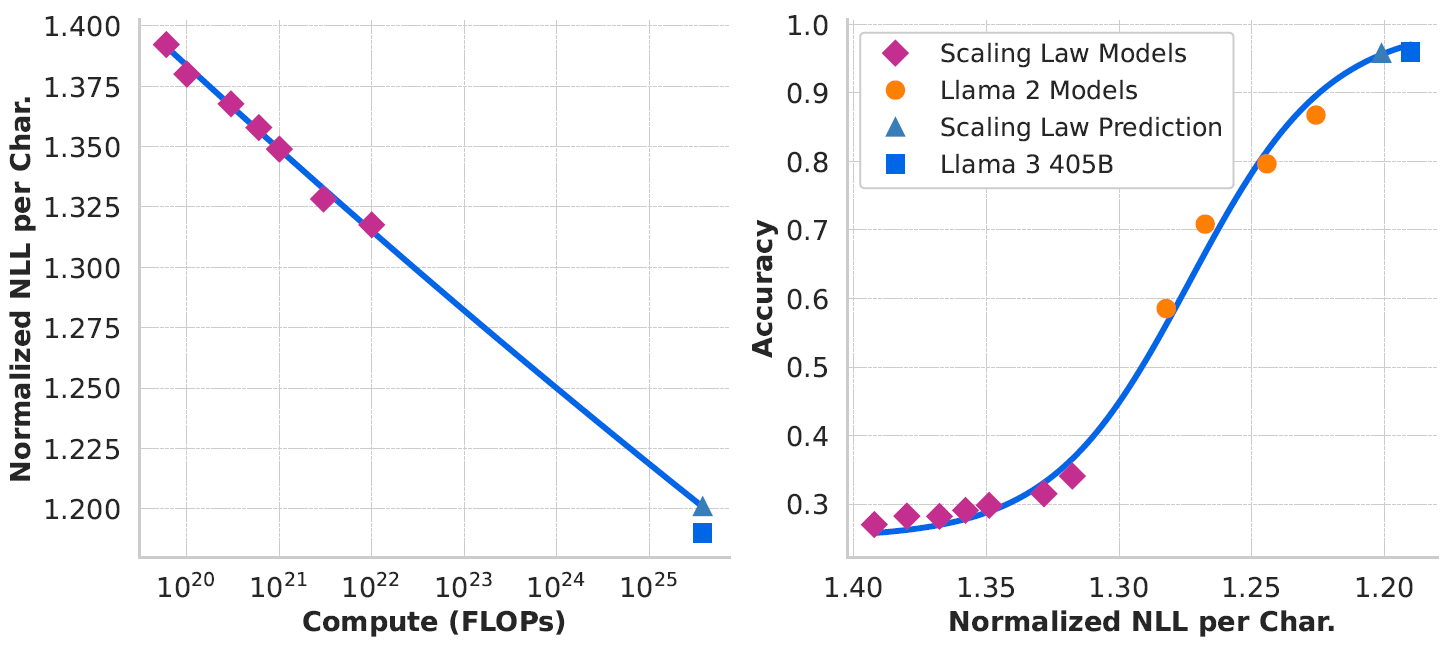
至此,我们已经可以不做任何训练,仅根据FLOPs就得到模型在ARC Challenge上的准确率了。牛不牛?
训练细节
论文列举了一些LLaMA3 405B的训练细节,比较有趣,可以指导我们自己的模型训练,这里也简要介绍。
逐步增大batch
初始化的batch为4M token;训完252M token之后调整batch为8M;训完2.87T token之后调整batch为16M。这样做可以提升训练稳定性,防止loss出现尖刺。
逐步增大序列长度
初始化的序列长度为8K,经过6个阶段,序列长度逐步变成128K。每个阶段都要评价当前的模型在更短序列上的表现,还要在当前序列长度的范围内做“大海捞针(needle in a haystack)”实验。只有这两项指标过关,才能增加序列长度,进入下一阶段。
调整数据混合配比
训练过程中一直在调整数据配比,例如增加非英语内容以提升跨语言能力,上采样数学内容以提升数学推理能力,在靠后的训练阶段增加近期网页内容以延长知识截至时间等。
结语
这篇论文干货太多,Facebook论文一贯如此,浓郁的工业风,深得我心。LLaMA3的预训练与其说是算法优化,不如说是工程优化。炼制大模型基座非一朝一夕,这是一项庞大的系统工程,任何一处短板都会让整个任务崩溃。
后续我会从微调角度继续分析LLaMA3是怎样练成的。