LLaMA3是怎样炼成的-对齐篇
llama 大模型 本文主要介绍LLaMA3的后训练。开局一张图:
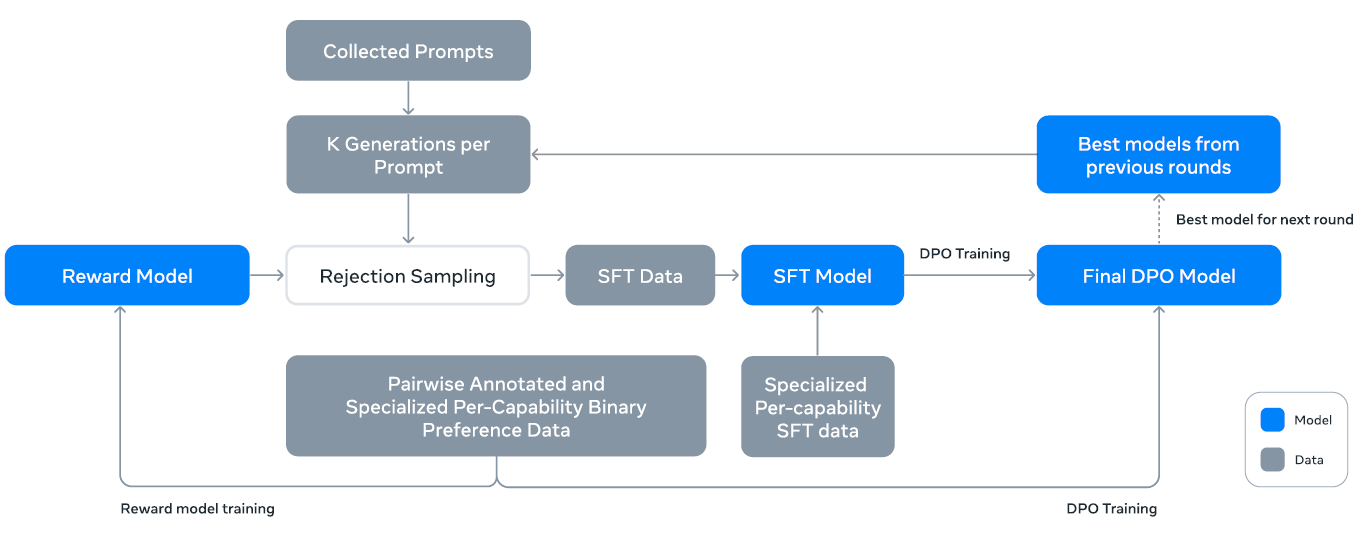
我知道你着急,但你先别急。先把下文看完,有助于看懂上图。
所谓“后训练”,就是让大模型对齐人类偏好的过程。这一过程主要包括SFT和RLHF。前面已经讲过大模型的基座是怎样预训练的,这回讲讲大模型是怎样对齐人类意图的。
大模型的对齐过程通常是这样的:用SFT在基座的基础上微调出一个初始策略模型,然后用RLHF不断优化。LLaMA2用的优化算法是PPO,LLaMA3换成了DPO。最后得到一个不错的策略模型,这就是我们想要的大模型。
在LLaMA3的后训练过程中,无论是SFT还是RLHF,都要依赖奖励模型:SFT用它做拒绝采样,RLHF用它反馈奖励值。所以,我们先看看奖励模型是怎样炼成的。
说明:LLaMA3和LLaMA3.1都属于LLaMA3系列。下文中,LLaMA3一般是指LLaMA3.1 405B。但是,很多用于合成训练数据的LLaMA3是指早期版本的LLaMA3,我懒得另外起名,请读者注意甄别。
奖励模型
以预训练阶段的checkpoint为基础,训练一个奖励模型。基础模型有了,现在只需再明确两件事:训练数据是啥?损失函数是啥?
训练数据
训练奖励模型需要人工标注偏好数据。这个过程和LLaMA2相同:标注员人工编写一条提示词,送给几个不同的大模型,然后随机采样两条回复。标注员给自己更加偏好的一条回复打上chosen标签,另一条打上rejected标签。
如果标注员认为chosen回复还不够好,他可以编辑chosen回复,得到一条质量更高的回复并打上edited标签。所以,回复标签有三种:edited>chosen>rejected。
不仅如此,标注员还要标注自己偏好的程度:significantly better, better,slightly better, marginally better。只有标注为significantly better或better的数据被用于训练奖励模型。
损失函数
在原始的InstructGPT论文中,奖励模型的损失函数如下:
\[L=-\log(\sigma(r_{\theta}(x, y_{c})-r_{\theta}(x, y_{r})))\]其中,\(x\)是提示词,\(\theta\)是模型参数,\(r_{\theta}(x,y)\)是奖励模型的评分,\(y_{c}\)是标注员选择的回复,\(y_{r}\)是标注员拒绝的回复。
后来,LLaMA2的作者们认为,标注的偏好相差越大,说明两个回复的差异越大,奖励模型给两个回复打分的差异就应该越大。于是,LLaMA2在损失函数中引入了一个边距\(m(r)\):
\[L=-\log(\sigma(r_{\theta}(x, y_{c})-r_{\theta}(x, y_{r})-m(r)))\]其中,\(r\)是标注的偏好等级(例如significantly better, better,slightly better, marginally better),\(m(r)\)是离散函数:偏好相差越大,\(m(r)\)越大。
然而,到了LLaMA3,研究人员发现当数据量足够大时,有没有\(m(r)\)效果差不多,于是兜兜转转,损失函数又恢复了原始面貌。
有了奖励模型,还需要一个初始策略模型。SFT闪亮登场。
SFT
SFT的损失函数就是标准的交叉熵(注意,计算损失时要遮盖提示词部分),没什么好讲的。我们来看看SFT的训练数据。
SFT的训练数据主要有三个来源:
- 人工编写提示词,对生成的回复做拒绝采样
- 针对各项特定能力专门合成的数据
- 少量人工治理的数据
关于第一个数据来源,人工编写的提示词在训练奖励模型时已经用过。那么,什么是“拒绝采样”(rejection sampling)?
名字有点怪,其实很简单:这里把提示词输入最新训出的策略模型,让模型生成K个回复(K一般在10-30之间),然后把K个回复输入奖励模型,选择得分最高的回复,与提示词一起组成一条训练数据。这个过程就叫“拒绝采样”。
关于第二个数据来源,LLaMA3论文花了大量篇幅介绍如何针对大模型的特定能力合成训练数据。特定能力是指诸如代码生成、多语言、数学推理、长上下文…论文给出许多“奇技淫巧”,在合成数据的过程中,有时也需要进行一些人工治理,即第三个数据来源。下面对各种特定能力的数据做简要介绍。
代码
负责合成代码数据的是一个专家模型,这个模型是从主预训练流程中分出一支来,用1T token(85%以上是代码)继续训练,最后几千步把上下文扩展到16K,用仓库级高质量代码数据做微调,然后对这个模型做后训练。可以看出,这个过程实际上就是训了一个CodeLlama。
有了专家模型,怎样生成代码?
从一些数据源采集代码,先让专家模型根据这些代码生成五花八门的编程问题,再用LLaMA3根据问题描述生成代码。这一来一回,生成的代码和问题描述就具有了多样性。
然而,如何保证生成代码的正确性?
这里采用的方法是“执行反馈”:一方面用代码检查工具静态分析语法错误、代码风格,检查结果是一种反馈;另一方面把问题描述和代码输入专家模型,让模型生成单元测试,然后执行,运行结果也是一种反馈。把这些反馈(可能是代码风格问题、运行报错等)作为提示词的一部分,和问题描述、代码一起送给专家模型,可以让模型修复代码,也让模型修改单元测试,总之最后只有通过测试的代码被用于SFT。
就这样,执行反馈让专家模型具有了生成正确代码的能力。但是,仅仅生成好代码是不够的,还要生成好文档、好注释。这又要怎么解决呢?
这里采用的方法是“回译”:让LLaMA3为一些代码生成文档和注释,然后让专家模型把文档或注释回译成代码,再把原始代码、生成的文档和注释、回译代码都输入LLaMA3,让它给回译代码的质量打分,高分文档和注释连同原始代码被用于SFT。
还有一个问题:有的编程语言样本量很少,怎么办?
答案是“翻译编程语言”。例如,Python很多,但是PHP很少,就用LLaMA3把Python翻译成PHP。当然,翻译之后也要检查语法、编译、执行等,保证翻译的准确性。
多语言
非英语的多语言训练数据主要包括德语、法语、意大利语、葡萄牙语、印地语、西班牙语、泰语。所以网上有些人用中文测评LLaMA3,结果不尽如人意。
多语言数据主要有4个来源:2.4%来自人工标注,标注员主要由语言学家和母语者组成,这种提示词的分布接近真实世界;44.2%来自其他NLP任务数据集,例如exams-qa数据集EXAMS,包含26种语言;18.8%来自拒绝采样,把人工标注提示词送入奖励模型,保留最好的模型输出作为训练数据;34.6%来自英语翻译,但是只翻译和数学推理相关的数据,因为数学推理的表达在各种语言种都是简明且严谨的,这样可以避免引入文化环境带来的偏差,例如我们所熟知的“翻译腔”。
数学推理
复杂数学推理问题的提示词比较稀少。为了解决这个问题,LLaMA3一方面把一些数学内容转成QA形式,另一方面也会评估当前的模型还缺乏哪些数学技巧,然后让标注员有针对性地编写提示词,提升数学技巧。
数学推理一般是逐步递进的,解题的中间步骤特别重要,所以要提升推理能力,需要用思维链数据训练模型。但是,思维链数据从哪来?
没错,还是用LLaMA3生成。对每个提示词都生成若干中间步骤和答案,然后保留答案正确的中间步骤。为了保证中间步骤的正确性,论文仿照Let’s Verify Step by Step这篇论文的做法,训练结果和过程监督奖励模型,过滤错误的中间步骤。
长上下文
预训练时,基座模型已经具备了相当好的长上下文能力。如果SFT仅用短上下文,会损害已有的长上下文能力。但是人工标注长上下文成本太高,所以这里同样使用合成数据。
常见的长上下文场景有哪些?问答、摘要、代码。所以,主要针对这三个场景合成数据。
先看问答。从预训练数据中挑选一些长文档,按8K大小切分成块,随机挑选一些块,基于这些块用LLaMA3生成问答对。做SFT时,全文和问题都要放入提示词。
再看摘要。用LLaMA3对每个8K大小的块摘要,然后对这些摘要再做一次摘要,作为全文摘要。做SFT时,把全文喂给模型,让模型生成全文摘要。另外,基于摘要生成问答对,进一步补充了问答场景的训练数据。
最后看代码。这里设计了一个非常有趣的任务:分析Python代码库,移除被import最多的文件。SFT时,让模型判断哪些文件依赖被移除的文件,并且生成被移除文件的代码。
实验发现,SFT时,在原有短上下文数据中混合0.1%的合成长上下文数据,模型效果最佳。而且,只要SFT的长上下文效果好,只用短上下文训练DPO,模型效果不受影响。所以最终模型在长上下文SFT的基础上,用短上下文训练DPO。
使用工具
不会使用工具的大模型只是聊天工具,会使用工具的大模型才能做各种助手。自从基于LLM的agent火起来之后,训练大模型时也要考虑如何有效与工具交互。
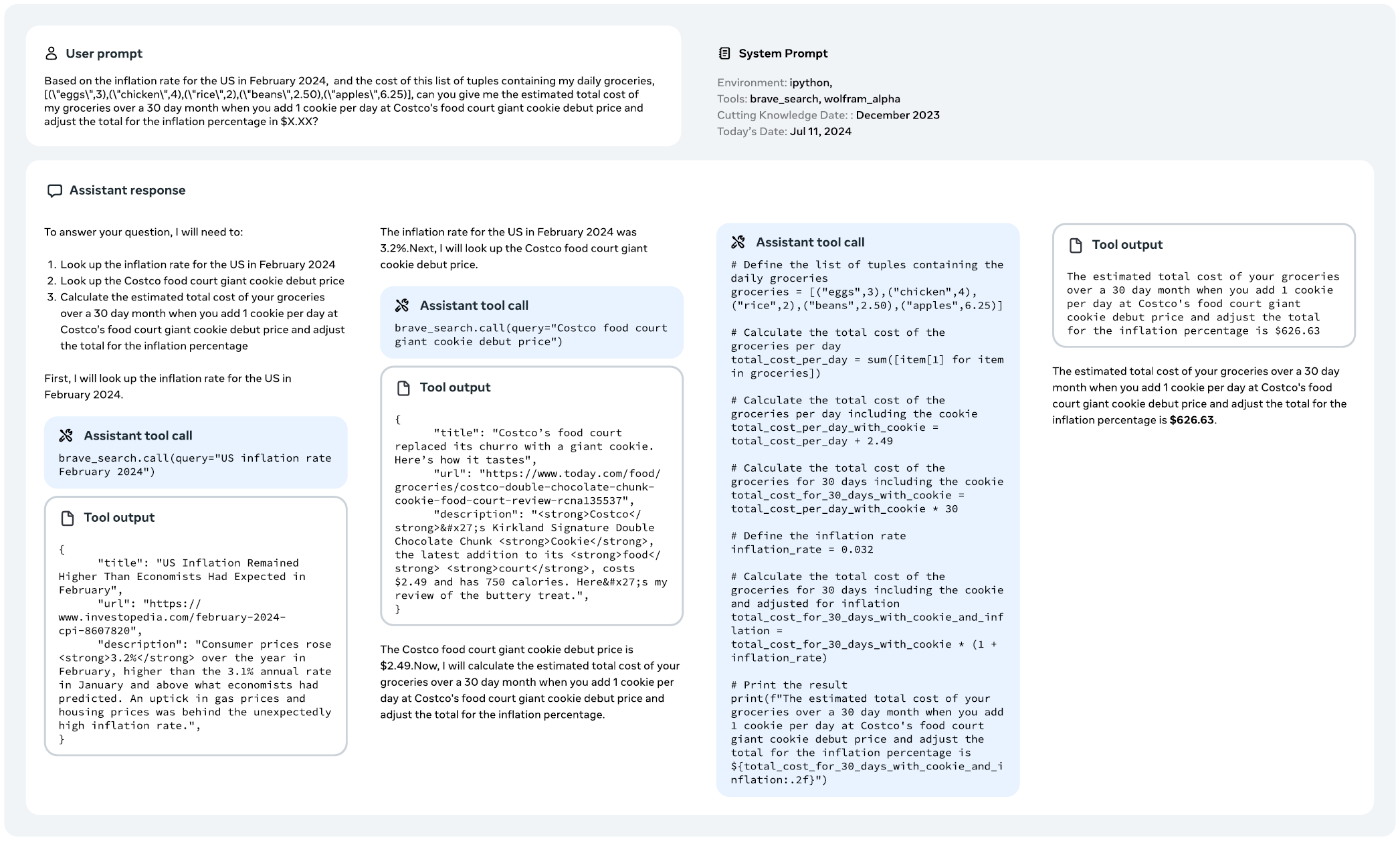
LLaMA3主要训练了与搜索引擎(Brave Search)、Python解释器和数学计算引擎(Wolfman Alpha)交互的能力。模型调用的工具都用Python函数实现,调用时要把函数签名(函数名+参数列表)放到上下文中,系统根据函数签名调用Python解释器执行函数。
有些问题只需要调用一次工具就能解决,有的则需要多次调用不同工具。以单次工具调用为例,先以few-shot的方式让LLaMA3生成只调用一次工具的提示词,然后以few-shot方式让LLaMA3为这些提示词生成工具调用。执行调用,得到工具输出,把输出加入上下文,让LLaMA3根据工具输出得到最终答案。于是,这一系列的上下文和答案,就成为SFT训练数据。
可以从下图感受一下LLaMA3是如何做多步推理,然后调用工具解决问题的:
事实性(Factuality)
在大模型领域,幻觉一直是个难题。LLaMA3的后训练遵从一个原则:know what it knows,即模型不要“臆造”知识,而应“知之为知之,不知为不知”。
论文用“知识探测”方法实现这一目标:从预训练数据中提取一个数据片段,让LLaMA3根据片段生成一个事实性问题,并让LLaMA3生成一些回复。然后用LLaMA3分别给回复的正确性和信息量分别打分。如果回复总是信息量很高但不正确,说明根据上下文无法回答生成的问题,这时让LLaMA3生成拒绝回复。
把这些问题和拒绝回复用于SFT,可以让模型产生一定的“自制力”,不要自行脑补,不要胡乱发挥,从而缓解幻觉现象。
可控性(Steerability)
LLaMA3的可控性主要来自系统提示词,实际上就是给模型设定角色。标注员为LLaMA3设计不同的系统提示词,然后和模型对话,评估模型遵从角色的程度。对于遵从程度好的系统提示词,收集偏好数据,训练奖励模型、拒绝采样、SFT和DPO。
通常,系统提示词写得越细致,效果越好。下图是一个系统提示词的例子,大家感受一下:

数据清洗和过滤
至此,我们已经有了一大堆用于SFT的训练数据。但是数据质量未必很高,例如在早期几轮训练中,模型总是过度生成emoji表情和感叹号、总喜欢表达歉意等。所以要用一些规则和策略清洗数据。
不仅如此,我们还要一套办法过滤低质量数据。例如,用奖励模型和LLaMA3给合成数据打分。奖励模型输出的分数中,位于首四分位数的数据认为是高质量。对于英文数据,LLaMA3从准确率、指令遵从、表达三个维度打分,对于代码数据,LLaMA3从bug识别、用户意图两个维度打分,得分高的数据认为是高质量。
总之,各种方法的目的只有一个,就是为SFT提供量大质优的训练数据。SFT负责生成一个初始策略模型,接下来要用RLHF继续优化。
RLHF
如前所说,LLaMA3做RLHF采用的方法是DPO,而LLaMA2采用的是PPO。为什么换算法了?因为实验发现DPO不仅计算量小,而且在指令遵从上表现更好,例如在指令遵从数据集IFEval上,DPO的效果优于PPO。可以想象,今后DPO可能就是RLHF标配了。关于DPO算法,我不打算展开讲,有空了另写文章。
最后
从上面的介绍可以看出,充分利用既有大模型生成人造数据,是LLaMA3完成后训练的关键。LLaMA3这篇论文就像一本cookbook,从数据到模型,介绍细致入微,值得反复研读。
现在,你可以翻到本文最上面,再看看那张后训练的流程图。懂了吗?