大语言模型的参数高效微调:适配器方法
大模型 微调 适配器 预训练大模型如何适配不同的下游任务?传统方法是在下游任务的特定数据集上做微调。这种微调会更新大模型的全部参数。从BERT开始(如果你想知道BERT有多少参数,请看这篇文章),到GPT-2、GPT-3、GPT-3.5,模型的参数量越来越大,传统的微调成本越来越高。
以在线训练服务为例,当服务接到多个训练任务时,理想的微调应该在各个任务之间共享大部分模型参数,每个任务只更新少量参数以适配自身需求。如果每个任务都更新模型全部参数,将会给模型训练、存储和部署带来较大负担。
适配器方法
令\(\phi_{w}(x)\)表示参数为w的预训练网络,适配下游任务的网络为\(\chi_{v}\),参数为v。传统的微调把两者结合在一起,可表示为\(\chi_{v}(\phi_{w}(x))\),微调时需要同时更新参数w和v。
适配器(Adapter)方法改变了微调的模式。它在预训练网络中插入称为“适配器”的若干层,把预训练网络从\(\phi_{w}(x)\)变成一个新网络\(\psi_{w,v}(x)\)。微调时保持w不变,只更新参数v。如果v的参数量远小于w,那么,与传统微调相比,需要更新的参数量大幅下降。这样就实现了“参数高效”(parameter-efficient)。
以Transformer为例,适配器方法在每个block中插入两个适配器模块,如下图所示:
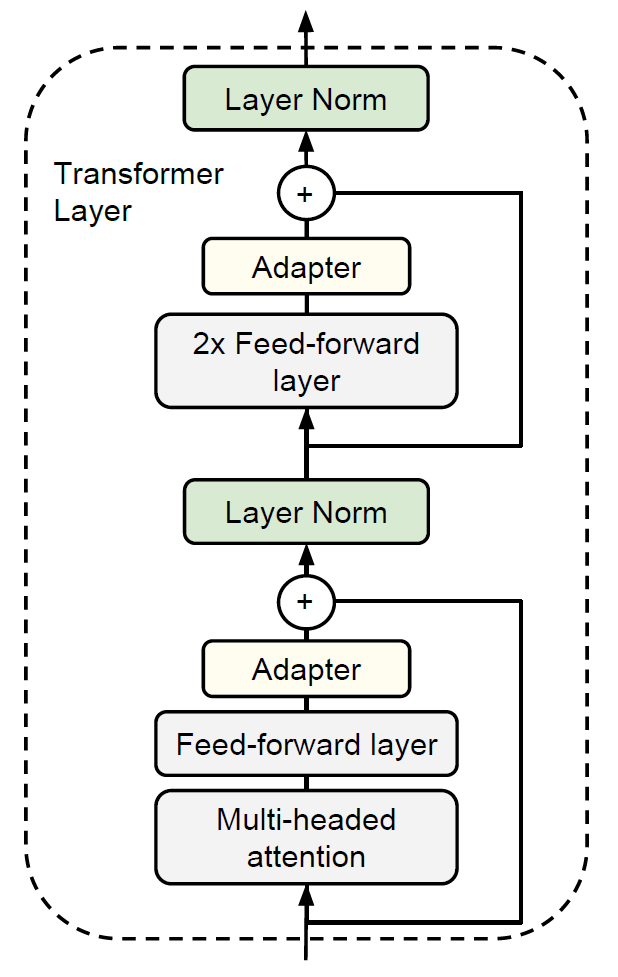
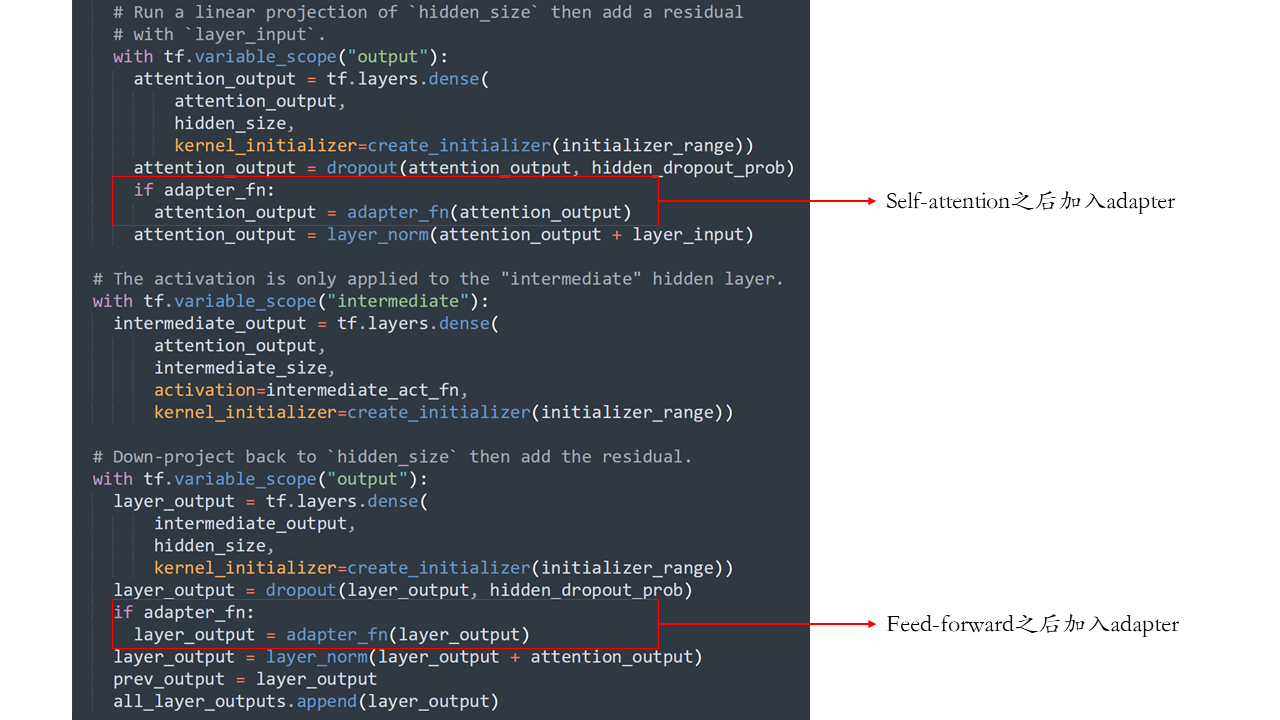
两个adapter分别位于两个前馈层之上:第一个前馈层把多头注意力的输出拼接之后映射到与输入向量等维度的空间中,第二个前馈层把上一层网络升维后的表示降维到与输入向量等维度的空间中。适配器论文代码的transformer_model函数提供了这部分的实现,如下图所示:
每个adapter的结构如下图所示:
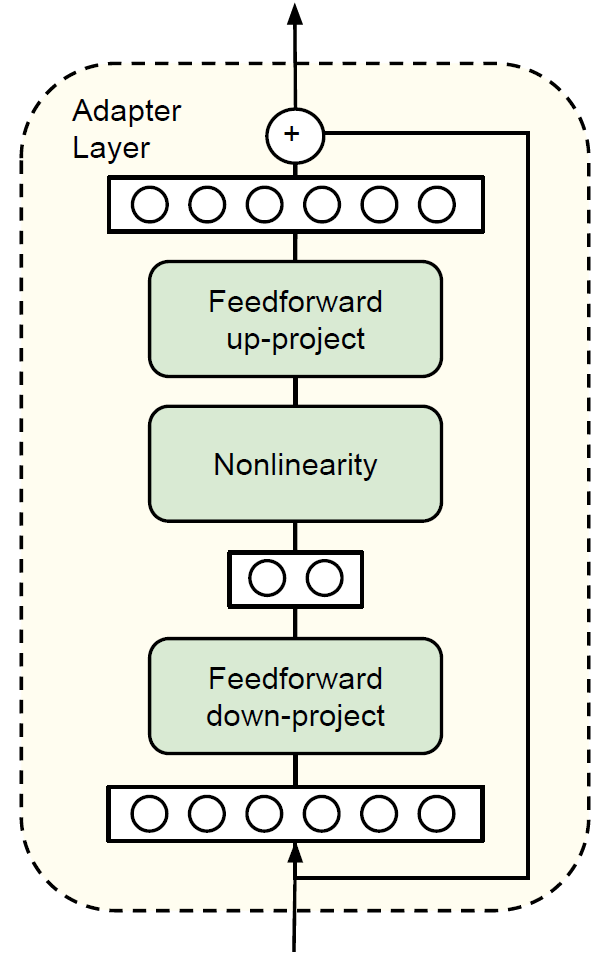
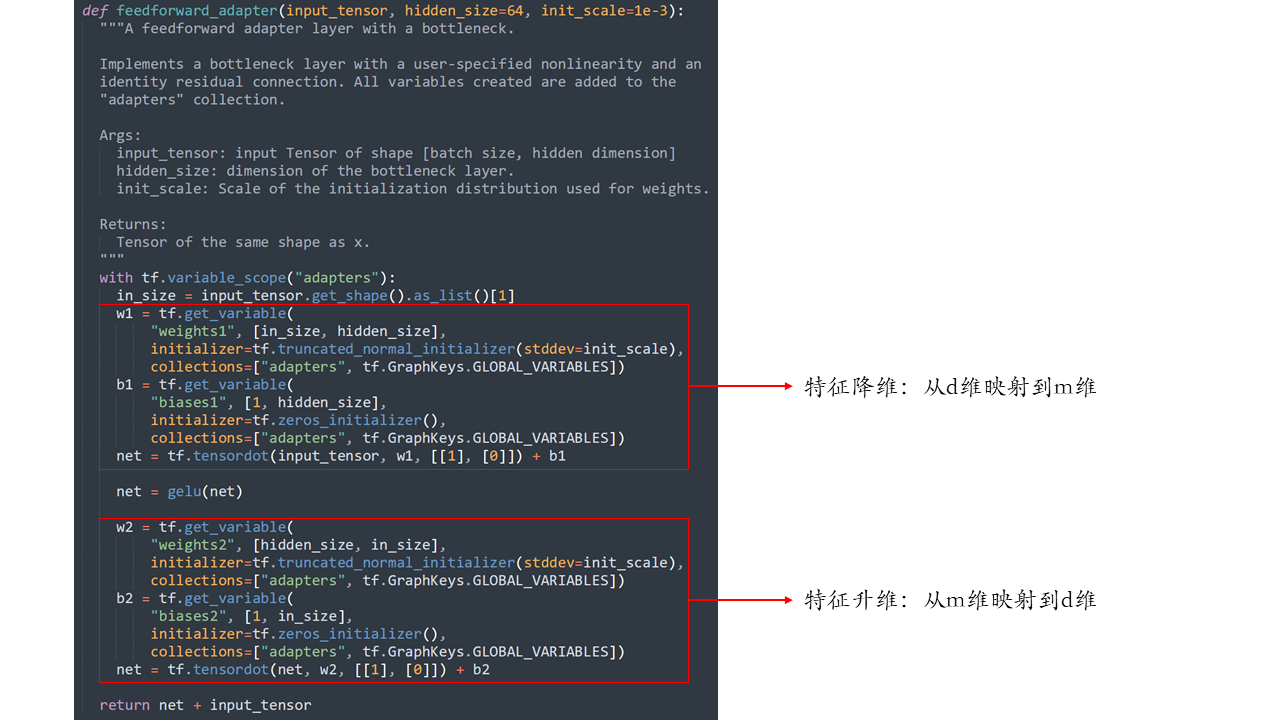
设Transformer的输入特征维度为d,适配器首先把特征从d维映射到m维,再从m维映射到d维,其中,\(m \ll d\),使adapter内部形成“瓶颈”结构。同时,适配器在输入和输出之间加了一条跳接,这个技术在ResNet和Transformer中都有使用。初始化时,如果adapter的两个映射矩阵都接近零矩阵,适配器就近似为一个恒等函数,即\(\psi_{w,v}(x) \approx \phi_{w}(x)\)。适配器论文代码的feedforward_adapter函数实现了adapter:
以BERT-base为例,输入特征维度d=768,若m=64,则一个adapter的参数量为2md + m + d = 99136,一层block加入2个adapter,新增参数总量为2 * 99136 = 198272。BERT-base共12层,因此,微调时需要更新的参数量为12 * 198272 = 2379264 \(\approx 2.4M\)。而传统微调需要更新预训练模型的全部109M参数(参考这篇文章),适配器方法仅需更新约2%的参数量。
适配器方法的缺点
Adapter有个比较明显的缺点:增加了网络层数,导致推理延迟增加。以GPT-2 medium为例,观察Adapter-H(即上文提到的适配器方法,由N. Houlsby等人提出)和Adapter-L(适配器方法的一个高效变体,由Lin等人提出)的推理延迟:
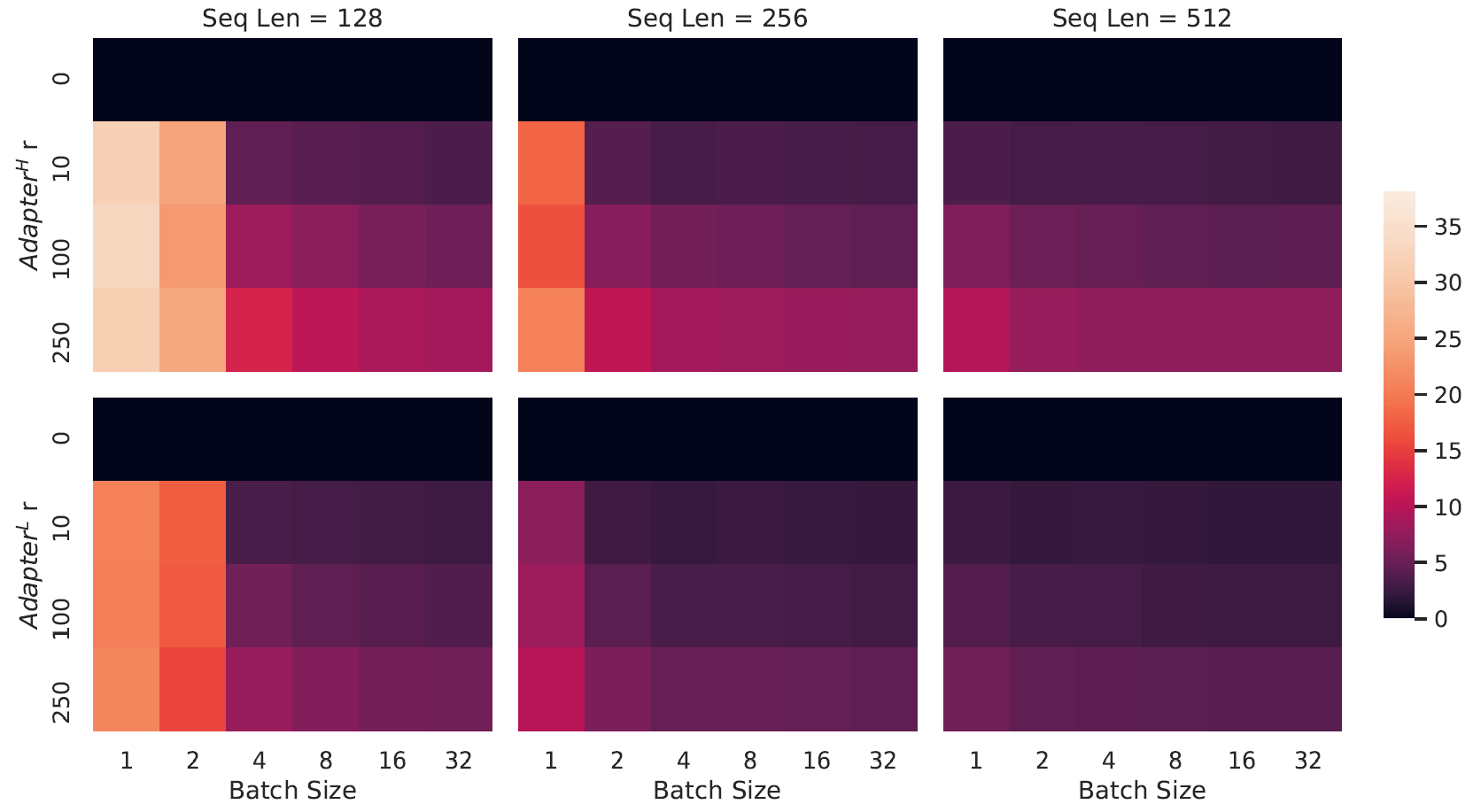
上图中,横轴是batch size,纵轴是adapter内部“瓶颈”的维度。颜色越深,表示相对于无适配器的GPT-2,推理延迟的增量越小。当“瓶颈”维度为0时,热力图颜色为黑色,表示无适配器的原始GPT-2。由上图可见,batch size越大,推理延迟增量越小;序列长度越长,推理延迟增量越小。但是,在实际线上场景中,batch size往往为1或很小,可能导致适配器方法微调的大模型比无适配器微调的大模型推理延迟增加超过30%。