多语言预训练模型-XLM和XLM-R
bert 大模型 在这篇文章中,我介绍了Google提出的多语言预训练模型m-BERT。Facebook紧随其后,分别于2019年和2020年提出了自己的多语言预训练模型XLM和XLM-R。
XLM
与BERT类似,XLM也使用Transformer的encoder部分做预训练,语料主要来自多种语言的Wikipedia。XLM的创新之处在于使用了三个预训练任务,对应三个目标函数:两个无监督目标和一个有监督目标。
两个无监督目标分别对应因果语言模型(Causal Language Modeling, CLM)和遮盖语言模型(Masked Language Modeling, MLM)。
- CLM:即标准的语言模型。给定一个单词序列,计算下一个单词出现的概率\(P(w_{t}\mid w_{1}, \cdots ,w_{t-1}, \theta)\)。
- MLM:即预训练BERT时采用的“完形填空”任务。从输入序列中随机选择15%的token,把这些token的80%用[MASK]替换,10%用随机token替换,10%保持不变。与BERT不同的是,这里MLM的输入不是句子对,而是“文本流”,即拼接任意数量的句子,超过256个token的部分截断即可。如下图所示:
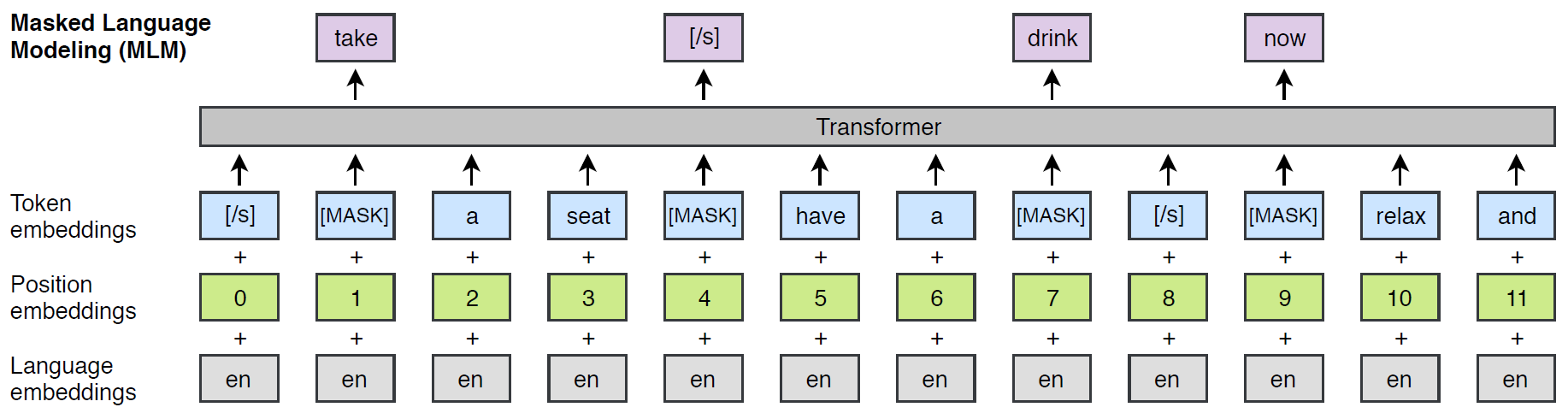
CLM和MLM只需要单一语言的语料即可进行无监督训练。如果有平行语料,则可利用有监督的翻译语言模型(Translation Language Modeling, TLM)进一步提升预训练模型的性能。
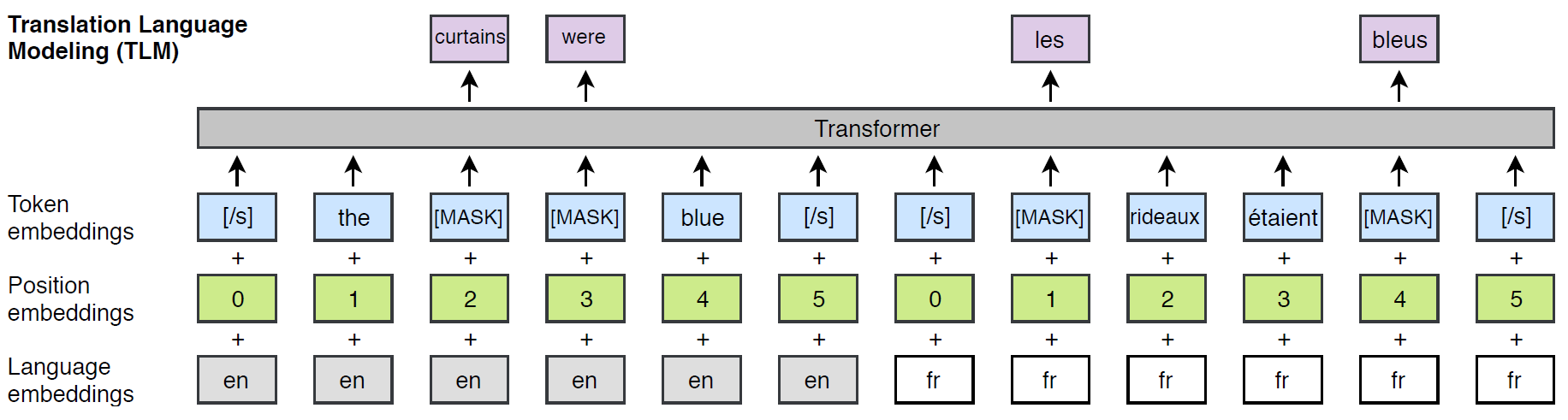
- TLM:与MLM类似,不同之处在于要把源语言和目标语言拼成一个序列输入模型,随机遮盖源语言和目标语言中的单词,这样做的好处是可以让模型充分学到两种语言的对齐信息,例如,预测源语言中被遮盖的单词时,可以同时利用源语言和目标语言中未被遮盖的部分。此外,源语言和目标语言的位置编码都是从0开始。如下图所示:
XLM用fastBPE构建了一个词表,所有语言共用这个词表。BPE需要一个原始词表作为输入,通过合并字符(或字,如中文)的方式,从原始词表中发现一些常用的子词,将这些子词加入原始词表。如此循环几轮,即可得到BPE词表。那么,原始词表是怎么来的呢?
原始词表的构建也很简单,只需对不同语言的句子做分词即可。XLM只对中文和泰文采用了特殊的分词器,其他语言使用同一种分词器。那么,不同语言的句子又是怎么来的?是从各语言的语料中采样得到的:从第\(i\)种语言采样句子的概率为
$$ q_i=\frac{p_{i}^{\alpha}}{\sum_{j=1}^{N}p_{j}^{\alpha}} $$
其中,
$$ p_i=\frac{n_{i}}{\sum_{k=1}^{N}n_{k}} $$
其中,\(n_{i}\)是第\(i\)种语言的句子总数。如果按照\(p_i\)从各种语言的语料中采样句子,高资源的语种被采样的概率较高,低资源的语种被采样的概率较低。如果低资源被采的句子特别少,BPE难以合并字符,最终的词表会出现许多单个字符,这样的词表不利于模型理解语义。因此,XLM引入了一个调节参数\(\alpha\),得到了一个新采样分布\(q_i\)。显然,当\(\alpha=1\)时,\(q_i = p_i\)。XLM把\(\alpha\)设为0.5,这样可以让低资源语言的句子获得更多的被采机会。
XLM-R
XLM-R是XLM-RoBERTa的缩写,因为这个模型受到RoBERTa的启发,采用了增大预训练语料规模、增大batch size等策略,使模型的跨语言性能达到较大提升。XLM-R与XLM之间的关系类似于RoBERTa和BERT之间的关系。XLM-R与XLM的主要不同之处有:
- XLM-R使用SentencePiece构建词表,避免了像XLM那样对不同语言使用不同分词器的操作。在XNLI上的实验表明,采用SentencePiece或BPE构建词表对模型的表现没有影响,如下图所示:
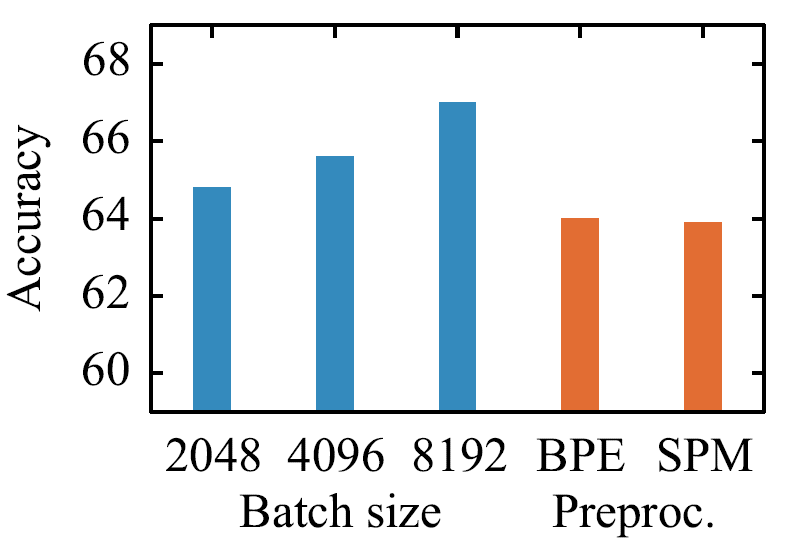
- 预训练XLM时,当验证集困惑度不再降低时就会停止训练,但XLM-R的实验表明验证集困惑度不再下降时继续训练能提升模型在下游任务上的表现。此外,增大batch size对性能提升也有帮助,如上图所示。基于这些改进,XLM-R在不使用TLM目标的情况下也能使模型在XNLI上的平均准确率达到和使用TLM的XLM持平,因此,XLM-R预训练时没有使用TLM目标。
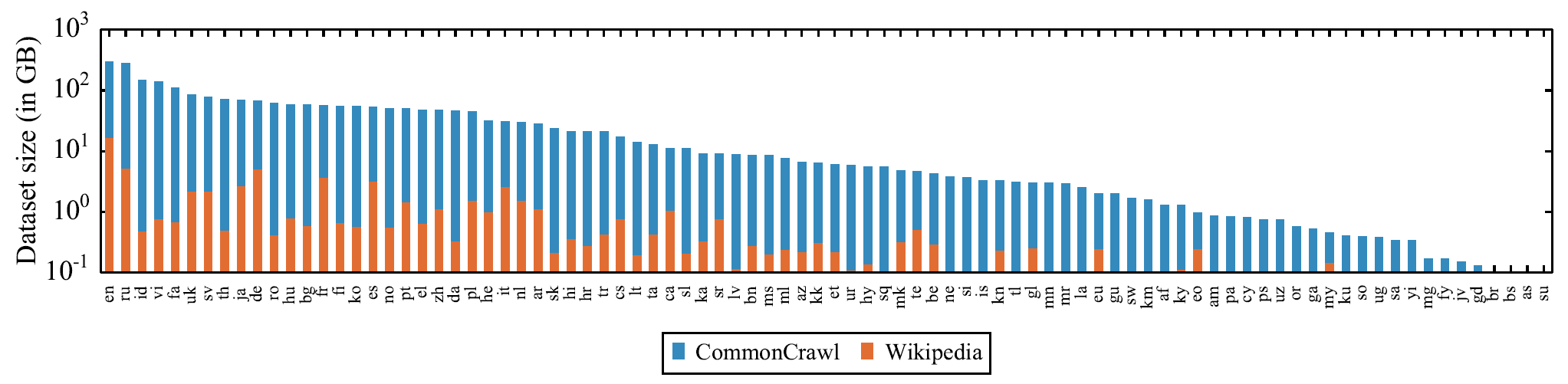
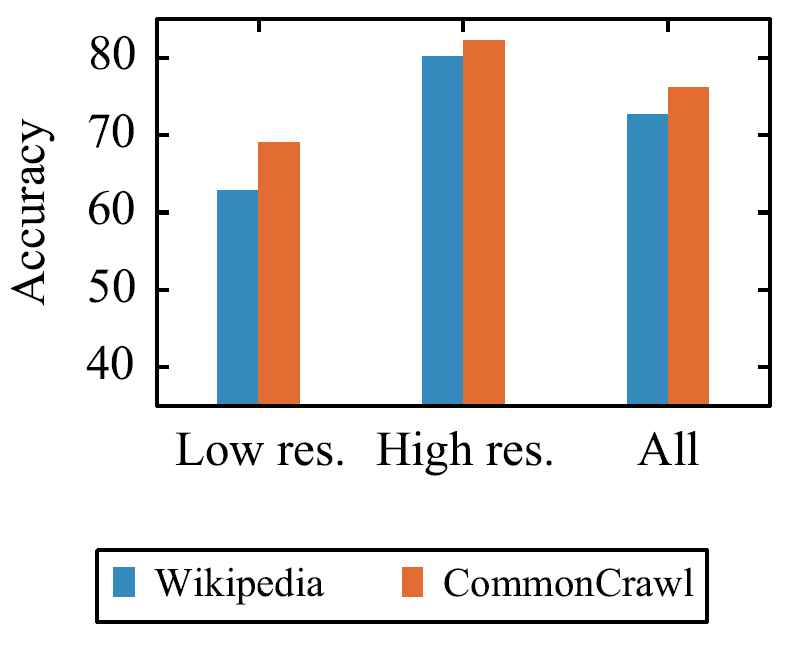
- XLM-R构建了一个包含100种语言的语料库CommonCrawl,语料规模超过XLM使用的Wikipedia语料库几个数量级,尤其是低资源语料。这两个语料库的对比如下图所示:
- XLM-R不使用语言嵌入。XLM在输入层加上了语言嵌入,但是XLM-R认为去掉这个嵌入可以更好地解决语码转换问题(可以参考我在这篇文章中的解释)。
除了上述差异,XLM-R这篇论文介绍了很多可以提升XLM性能的实验发现:
- 对于一个固定参数量的跨语言模型,当预训练语言的数量增加,每种语言占有的参数量(即容量)就会减少(即被稀释)。预训练跨语言模型时,虽然增加一些与低资源语言相似的高资源语言可以增强模型对低资源语言的理解能力,从而提升模型性能,也要考虑增加语言数量后对每种语言的稀释。从下图可以看出,在XNLI数据集上,当语言数量从7增加到15时,无论是低资源语言准确率还是模型整体准确率都有提升。如果继续增加语言数量,就会出现“多语言诅咒”(curse of multilinguality)现象,高资源和低资源语言的准确率都开始下降。
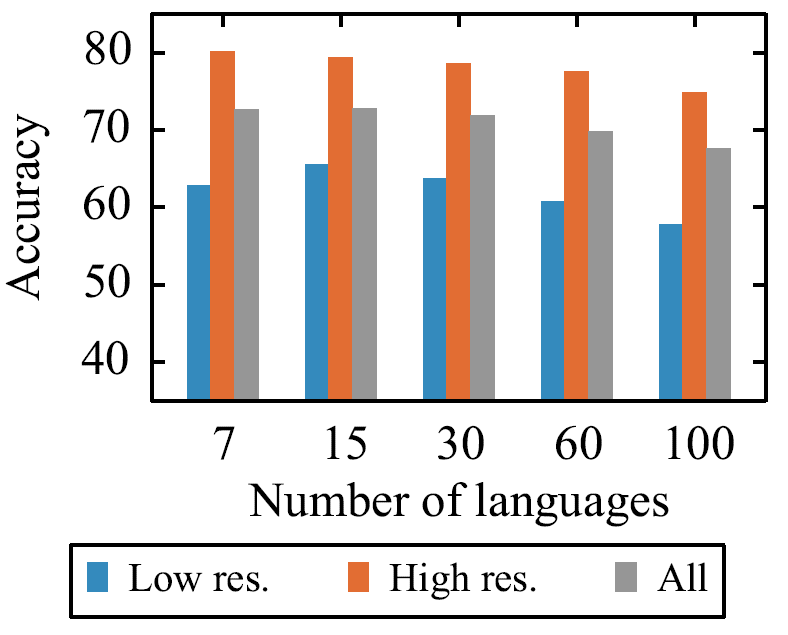
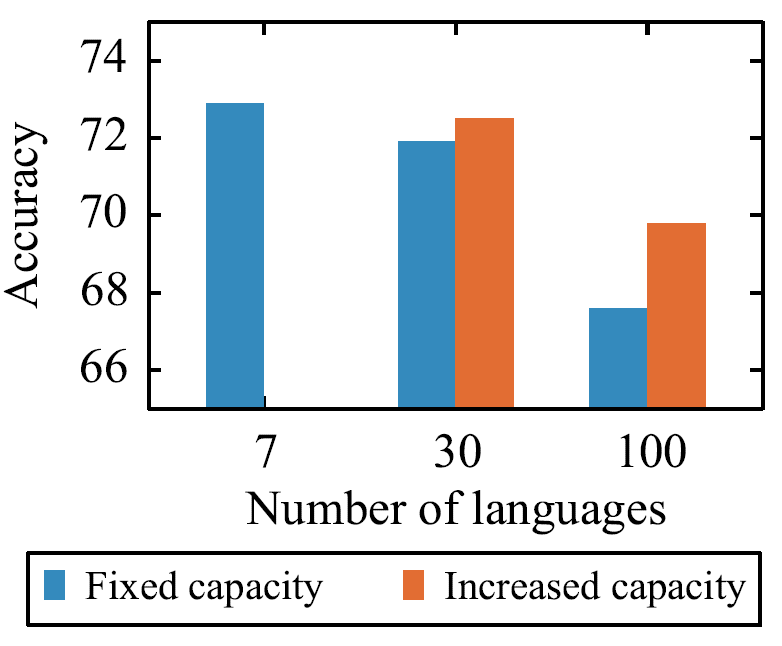
- 增大模型容量可以缓解多语言诅咒。下图中,如果固定模型容量(\(d_{model}=768\)),语言从7种增加到30种时,模型准确率下降较多,但是如果增大模型容量(\(d_{model}=960\)),30种语言的准确率和7种语言的准确率基本持平。当语言增加到100种时,固定容量的模型准确率较低,虽然增加模型容量(\(d_{model}=1152\))可以得到缓解,但准确率依然不高。
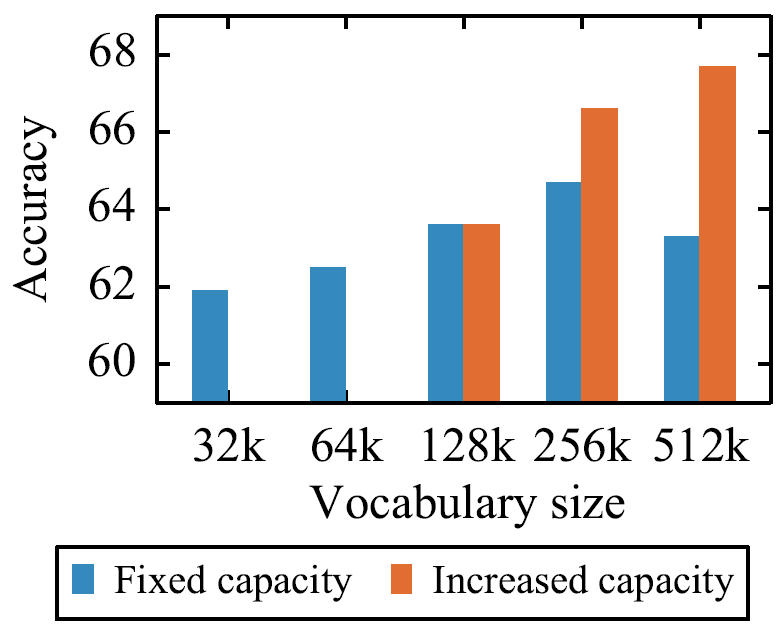
- 增大词表可以提升模型性能。下图中,把词表从32K增大到256K,同时减小模型宽度(即\(d_{model}\)),使模型容量保持不变,仍然可以看到准确率持续提升。如果放开模型容量的限制,把词表从128K增大到512K,准确率提升超过3%。
- 扩大语料规模可以提升模型性能。这一发现与RoBERTa相似,XLM-R构建了CommonCrawl,规模远大于XLM使用的Wikipedia。基于相同的BERT-base结构,使用CommonCrawl语料预训练的XLM-7(包含7种语言的XLM)性能明显优于使用Wilipedia预训练的XLM-7性能,尤其是在低资源语言上的表现,如下图:
- 采样语料时,增大\(\alpha\)可以提升模型在高资源语言上的表现,但是会降低模型在低资源语言上的表现。原因很简单,增大\(\alpha\)使高资源语言获得更多采样机会。权衡之后,XLM-R设置\(\alpha\)为0.3。下图展示了训练XLM-100(包含100种语言的XLM)时,通过调节\(\alpha\)可以影响模型在高资源和低资源语言上的表现。
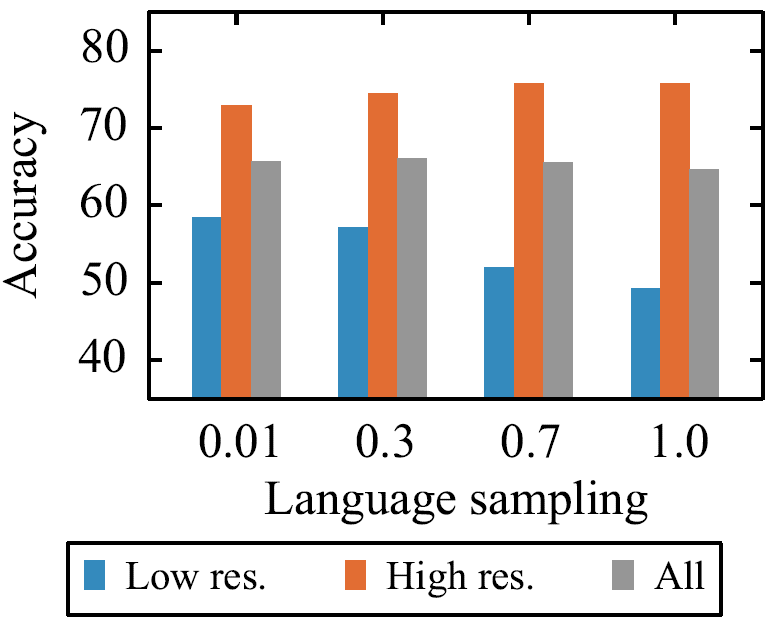
具体的实验结果这里不做介绍。值得一提的是,在XNLI和GLUE上,XLM-R的性能不输于在单语言上微调的RoBERTa的性能。XLM-R使得只使用一个预训练模型处理多语言任务而不牺牲每一种语言的性能成为可能。