从GPT到LLaMA再到LLaMA2
大模型 gpt llama 在大模型发展史上,LLaMA是值得写上一笔的。大模型的火是ChatGPT烧起来的,但是如果没有LLaMA的及时开源,这把火也难以形成燎原之势。从GPT到LLaMA再到LLaMA2,模型发生了哪些变化?它们之间有何不同?
GPT
故事从GPT讲起。GPT的结构就是去掉cross attention的Transformer decoder,如下图所示:
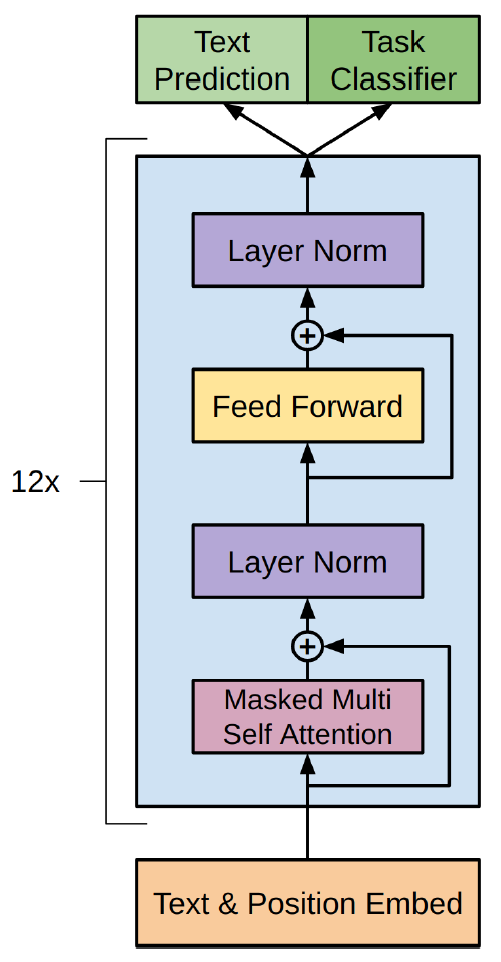
当然,GPT对Transformer的改变不止于此,例如,使用绝对位置编码替代正弦位置编码,使用GELU替代ReLU等。GPT-2在GPT的基础上又做了改进,把LayerNorm从输出移到了输入,即pre-normalization。GPT-3沿用了GPT-2的结构,秉承“大力出奇迹”的朴素思想,把参数量提升到175B。
这些改变看上去平平无奇,谁料命运的齿轮就此开始转动。GPT-2、GPT-3展示了强大的in-context learning能力,一直到基于GPT-3.5的ChatGPT横空出世,引爆学术和产业两界。
LLaMA
接着,LLaMA带着打破OpenAI垄断的使命出现了。LLaMA与先前工作的不同之处主要体现在三方面:
- 使用RMSNorm替代LayerNorm做pre-normalization
- 使用SwiGLU替代ReLU做激活函数
- 使用RoPE替代绝对位置编码
上面的每一条都有其他模型使用过,例如,GPT-2和GPT-3用过pre-normalization,PaLM用过SwiGLU,GPTNeo用过RoPE。然而,在大力出奇迹的时代,技巧大杂烩也可以大放异彩,关键要看你的力够不够大。于是,LLaMA的架构就变成下面的样子(图片来自这里):
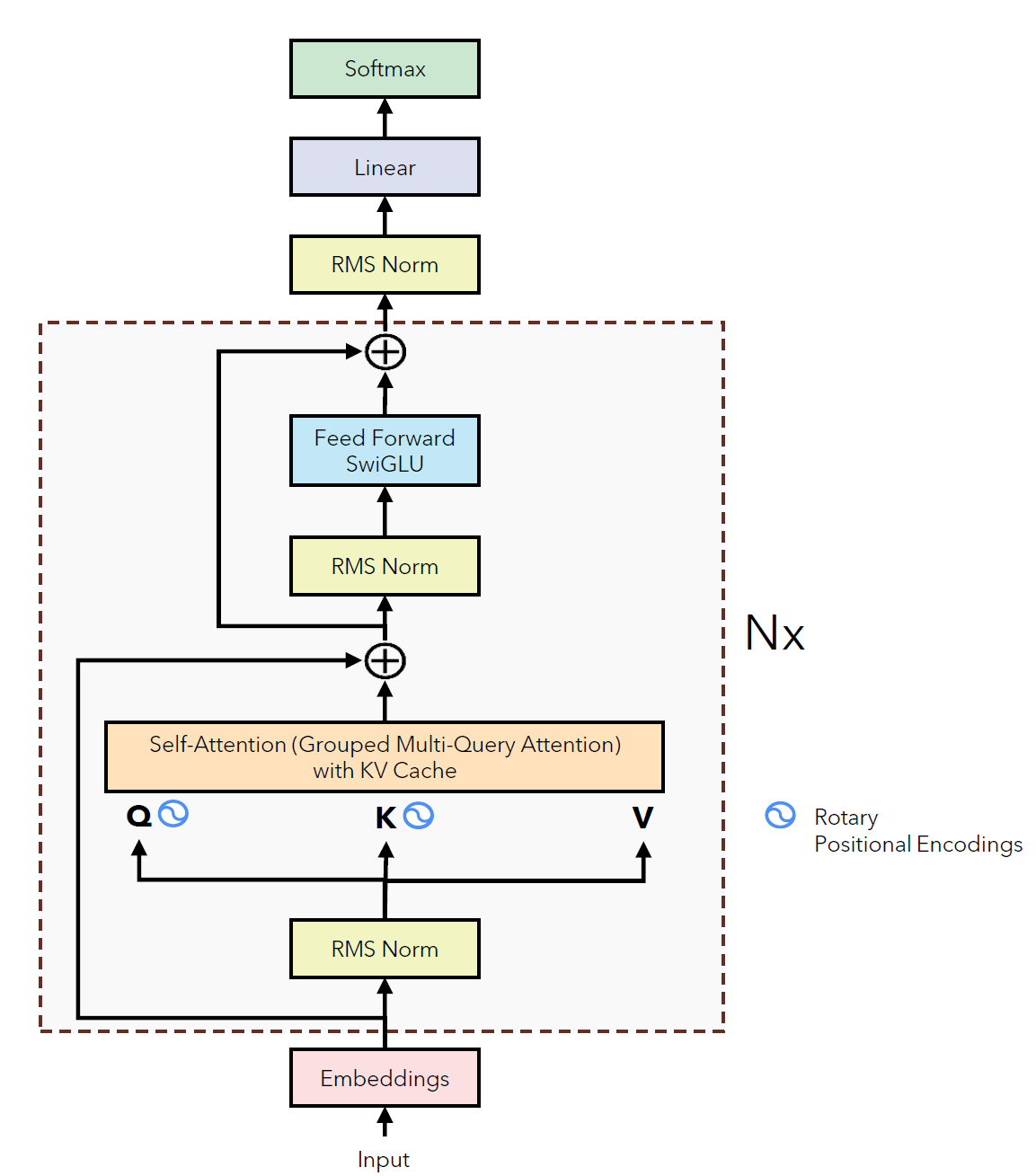
由于RoPE要说的东西比较多,另写文章介绍。这里只简单介绍SwiGLU和RMSNorm。
SwiGLU
SwiGLU是GLU(Gated Linear Units)的一个变体。严格地说,GLU不是激活函数,而是一层网络,它通过门控机制调节传递到下一层网络的信息量。设输入为\(\mathbf{x}\),\(\mathbf{W, V}\)是权重矩阵,\(\mathbf{b, c}\)是偏置向量,则GLU可以表示为:
\[GLU(\mathbf{x, W, V, b, c})=\sigma(\mathbf{xW+b})\otimes (\mathbf{xV+c})\]其中,\(\sigma\)是sigmoid函数。把上面的sigmoid替换为\(Swish_{\beta}\)(也叫SiLU)激活函数,就得到了SwiGLU:
\[SwiGLU(\mathbf{x, W, V, b, c})=Swish_{\beta}(\mathbf{xW+b})\otimes (\mathbf{xV+c})\]其中,\(Swish_{\beta}(\mathbf{x})=\mathbf{x}\sigma(\beta\mathbf{x})\),\(\beta\)可以是固定值,也可以通过学习得到。例如,固定\(\beta=1\),则激活函数为\(Swish_{1}(\mathbf{x})=\mathbf{x}\sigma(\mathbf{x})\)。
最初Transformer用ReLU激活FFN:
\[FFN(\mathbf{x, W_{1}, W_{2}, b_{1}, b_{2}})=ReLU(\mathbf{xW_{1}+b_{1}})\mathbf{W_{2}+b_{2}}=\max(0, \mathbf{xW_{1}+b_{1}})\mathbf{W_{2}+b_{2}}\]后来T5去掉了偏置:
\[FFN_{ReLU}(\mathbf{x, W_{1}, W_{2}})=ReLU(\mathbf{xW_{1}})\mathbf{W_{2}}=\max(0, \mathbf{xW_{1}})\mathbf{W_{2}}\]到了LLaMA,FFN的“激活方式”变为:
\[FFN_{SwiGLU}(\mathbf{x, W_{1}, V, W_{2}})=SwiGLU(\mathbf{x, W_{1}, V})\mathbf{W_{2}}=(Swish_{1}(\mathbf{xW_{1}})\otimes \mathbf{xV})\mathbf{W_{2}}\]RMSNorm
RMSNorm可以看作是LayerNorm的简化版。所以,这里首先回顾一下LayerNorm,如果想详细了解,可以看我写的另一篇文章。
以全连接前馈网络为例,设输入向量\(\mathbf{x}\in\mathbb{R}^{m}\),输出向量\(\mathbf{y}\in\mathbb{R}^{n}\),中间的计算过程是这样的:
\[a_{i}=\sum\limits_{j=1}^{m}w_{ij}x_{j}\] \[y_{i} = f(a_{i}+b_{i})\]其中,f是激活函数。先计算所有\(a_{i}\)的均值\(\mu\)和方差\(\sigma\):
\[\mu=\frac{1}{n}\sum\limits_{i=1}^{n}a_{i}\] \[\sigma=\sqrt{\frac{1}{n}\sum\limits_{i=1}^{n}(a_{i}-\mu)^2}\]接着做LayerNorm:
\[\bar{a}_{i}=\frac{a_{i}-\mu}{\sigma}g_{i}\] \[y_{i} = f(\bar{a}_{i}+b_{i})\]RMSNorm省去了计算均值的步骤,即RMS不需要re-centering(实际上,RMSNorm论文也做实验验证了re-center不重要,LayerNorm被打脸):
\[\bar{a}_{i}=\frac{a_{i}}{RMS(\mathbf{a})}g_{i}\] \[RMS(\mathbf{a})=\sqrt{\frac{1}{n}\sum\limits_{i=1}^{n}a_{i}}\]总之,用了上面介绍的几个技巧,LLaMA-13B的效果号称可以打败GPT-3(175B),这里不做深究,知道LLaMA很强就是了。
LLaMA2
2023年12月,LLaMA2出来了。与LLaMA1的架构基本相同,不同之处主要有两个:一是上下文长度从2048增加到了4096,二是用了一种新型注意力机制GQA(Grouped-Query Attention)。
增加上下文长度不仅提升了LLaMA的性能,而且拓宽了它的应用场景,这是一个非常直观的改进。GQA比较复杂,涉及到KV-cache等概念,这里做个简单介绍。
KV-cache
要说GQA,不得不先说说KV-cache。众所周知,GPT在时间步t生成的token会和[0, t-1]时间步生成的所有token拼接在一起,作为下一个时间步的输入。我们以输入money is all you need为例,模拟GPT的自回归过程:
- 输入:[BOS],输出:money
- 输入:[BOS, money],输出:is
- 输入:[BOS, money, is],输出:all
- 输入:[BOS, money, is, all],输出:you
- 输入:[BOS, money, is, all, you],输出:need
- 输入:[BOS, money, is, all, you, need],输出:EOS
以上面的第3步为例,GPT首先把输入的三个token向量与\(W^{Q}, W^{K}, W^{V}\)相乘,得到Q、K和V向量,然后用QKV计算注意力,得到表示这三个token的新向量并输出。
这时,细心的你一定会发现,在第3步计算”BOS”和”money”的Q、K、V向量好像没必要。因为这些向量在第2步已经算过了,何必在第3步重新算一遍呢?真正需要在第3步计算的,只有新增的”is”的Q、K和V向量。然后,GPT分别计算”is”的Q向量和”BOS”、”money”、”is”的K向量的点积,再与”is”的V向量相乘,就能得到”is”的注意力值了。在此过程中,”BOS”和”money”的注意力值保持不变。
于是,你的脑海中自然而然地产生了一个想法:为什么不把第1步和第2步已经算过的K和V向量全部重缓存起来,在第3步中直接使用呢?恭喜你,答对了,这就是KV-cache!
为了更好地理解KV-cache,我们看两段示例代码。第一段是没有使用KV-cache的原始多头注意力:
Q = torch.randn(N, h, S, d_k)
K = torch.randn(N, h, L, d_k)
V = torch.randn(N, h, L, d_k)
# <...>
logits = torch.matmul(Q, K.transpose(2, 3)) # Output shape [N, h, S, L]
softmax_out = torch.softmax(logits / math.sqrt(d_k), dim=-1) # Output shape [N, h, S, L]
attn_out = torch.matmul(softmax_out, V) # Output shape [N, h, S, d_k]
其中,h是head数量,S和L分别是query和key的序列长度(对于自注意力有S=L),d_k是模型隐层维度。可以看到,输出attn_out包含了每个token的注意力值,共S个。
再看第二段代码,这次使用了KV-cache:
# Cached K and V values across iterations
K = torch.randn(N, h, ..., d_k)
V = torch.randn(N, h, ..., d_k)
# Single-step QKV values computed during sequence generation
Q_incr = torch.randn(N, h, 1, d_k)
K_incr = torch.randn(N, h, 1, d_k)
V_incr = torch.randn(N, h, 1, d_k)
# <...>
# Update KV-cache
K = torch.cat([K, K_incr], dim=-2)
V = torch.cat([V, V_incr], dim=-2)
# Compute attention (L is sequence length so far)
logits = torch.matmul(Q_incr, K.transpose(2, 3)) # Output shape [N, h, 1, L]
softmax_out = torch.softmax(logits / math.sqrt(d_k), dim=-1) # Output shape [N, h, 1, L]
attn_out = torch.matmul(softmax_out, V) # Output shape [N, h, 1, d_k]
可以看到,这次只计算新增token的Q(即Q_incr)与先前所有token的K的点积,输出attn_out只包含一个新增token的注意力值。
GQA
KV-cache确实提升了Transformer decoder的推理速度,但是随着输入变得越来越长,KV-cache会给存储带来很大负担。所以,Google在2019年提出了Multi-Query Attention (MQA),不同的注意力头仍使用不同的Q向量,但使用同一个K和V向量:
# Cached K and V values across iterations
K = torch.randn(N, ..., d_k)
V = torch.randn(N, ..., d_k)
# Single-step QKV values computed during sequence generation
Q_incr = torch.randn(N, h, 1, d_k)
K_incr = torch.randn(N, 1, d_k)
V_incr = torch.randn(N, 1, d_k)
# <...>
# Update KV-cache
K = torch.cat([K, K_incr], dim=-2)
V = torch.cat([V, V_incr], dim=-2)
# Compute attention (L is sequence length so far)
# NB: K is broadcasted (repeated) out across Q's `h` dimension!
logits = torch.matmul(Q_incr, K.transpose(2, 3)) # Output shape [N, h, 1, L]
softmax_out = torch.softmax(logits / math.sqrt(d_k), dim=-1) # Output shape [N, h, 1, L]
# NB: V is broadcasted (repeated) out across softmax_out's `h` dimension!
attn_out = torch.matmul(softmax_out, V) # Output shape [N, h, 1, d_k]
可以看到,新增token的Q(即Q_incr)包含了h个注意力头,但K_incr和V_incr各自只包含了一个注意力头。因此,KV-cache的缓存量变为原来的1/h。
然而,原本K和V都有h个头,MQA简化到各剩一个头,模型性能受到损失。而原始的多头注意力MHA又会使KV-cache占用太多存储。怎么办?Google再次站出来,提出了“折中”方案Grouped-Query Attention (GQA)。
GQA的思路简单粗暴:用原始MHA,每个K和V有多个注意力头,你嫌占内存;用MQA,每个K和V只有一个注意力头,你嫌性能有损失。那么索性把Q的h个注意力头分成几组,每个组对应一个K和V,这样既不会占用太多内存,也不会损失太多性能。
下图对比了原始多头注意力MHA、多查询注意力MQA和分组查询注意力GQA三种注意力机制:
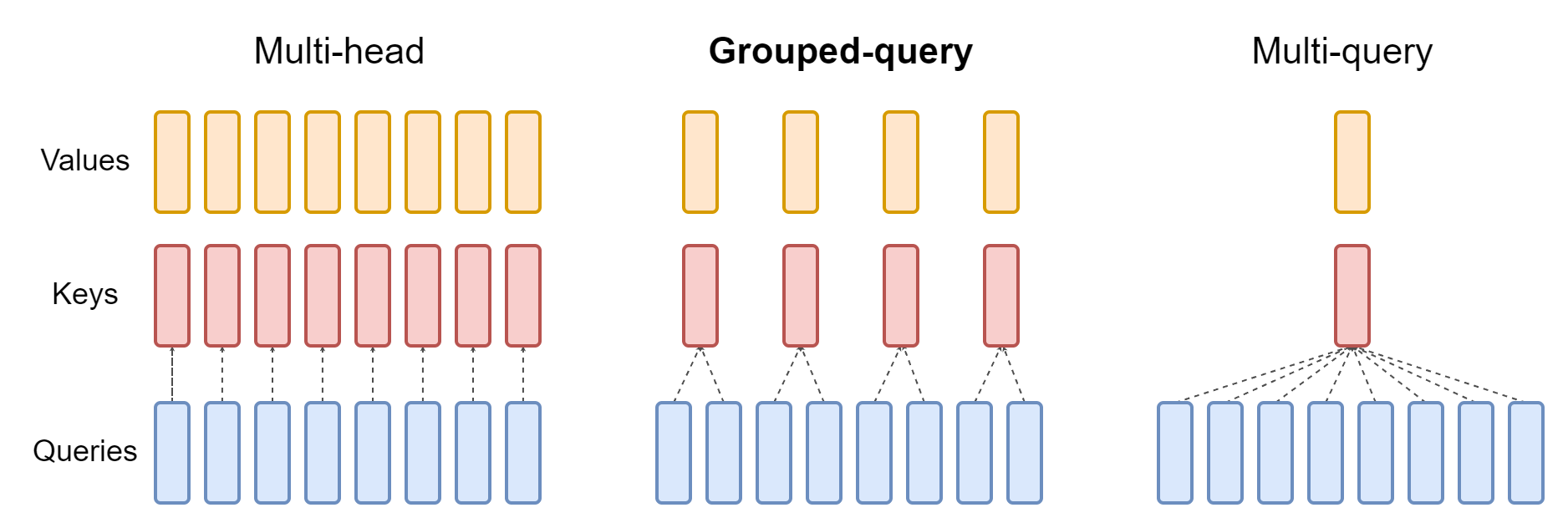
可以看出,GQA的机制是Q的若干个注意力头组成一组,共享同一个K和V。
感悟
大力出奇迹的时代,仅仅靠堆砌“奇技淫巧”就能获得良好收效。如果你像王思聪一样有钱,随便搞点创意加到项目上,项目效果可能都会被指数级放大。最大的问题是,如何成为王思聪?