大语言模型的参数高效微调:前缀微调
大模型 微调 与p-tuning,prompt tuning等方法类似,前缀微调(prefix tuning)也是一种软提示微调。前文已经介绍过一些软提示,所以这篇文章直接介绍prefix tuning的核心思路。
原理
顾名思义,prefix tuning就是给输入添加前缀,通过更新前缀的参数实现模型微调。设模型的输入和输出分别为x和y,对于自回归模型(如GPT),添加前缀后得到\(z=[PREFIX;x;y]\):

对于encoder-decoder模型(如BART),因为要同时微调encoder和decoder,所以encoder和decoder都要添加前缀,得到\(z=[PREFIX;xPREFIX';y]\):
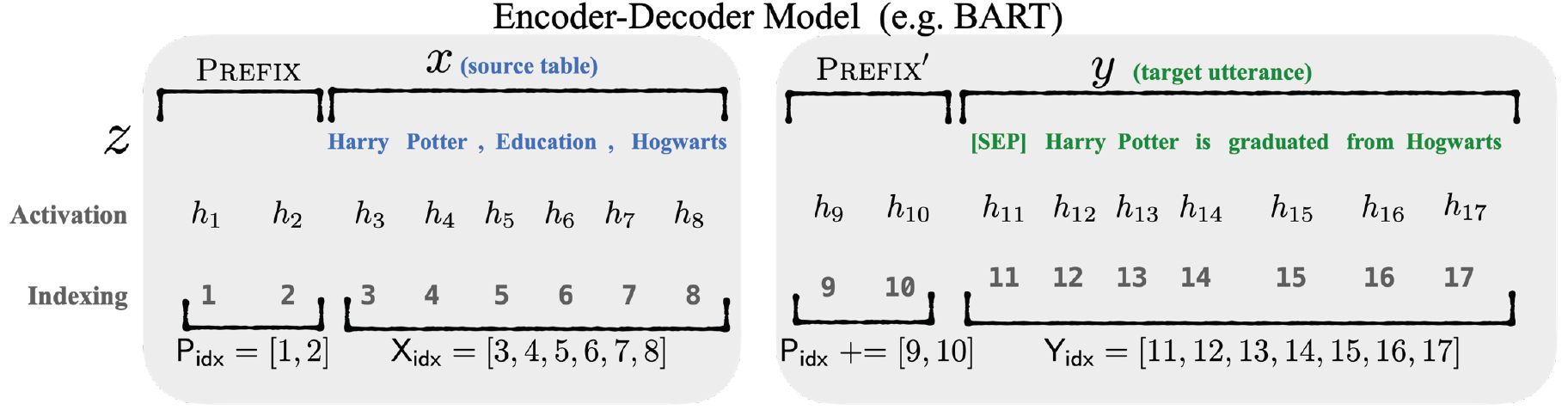
前缀的虚拟token从哪来?与prompt tuning类似,初始化一个形状为\(\lvert \mathbf{P}_{idx} \rvert\times dim(h_{i})\)的嵌入矩阵\(P_{\theta}\),其中,\(\mathbf{P}_{idx}\)是前缀序列对应的下标,\(h_{i}\)是输入序列中第\(i\)个位置对应的激活向量。
与以往介绍的软提示方法只更新嵌入矩阵不同,prefix tuning不仅更新嵌入矩阵,而且更新每一层前缀位置对应的参数。换言之,prefix tuning“拓宽”了模型,在模型每一层前面都插入了与前缀长度相同的参数。与只更新嵌入矩阵相比,由于增加了参与微调的参数量,所以能获得更好的表示能力。
论文还指出,直接更新\(P_{\theta}\)会导致优化过程不稳定,模型性能轻微下降。因此,需要引入一个更小的嵌入矩阵\(P'_{\theta}\),通过一层MLP变换为\(P_{\theta}\),即重参数化(reparameterization)。\(P_{\theta}\)和\(P'_{\theta}\)行数相同,列数不同,即\(P_{\theta}[i,:]=MLP(P'_{\theta}[i,:])\)。训练完成后,\(P'_{\theta}\)和MLP可以丢弃,只保存\(P_{\theta}\)即可。
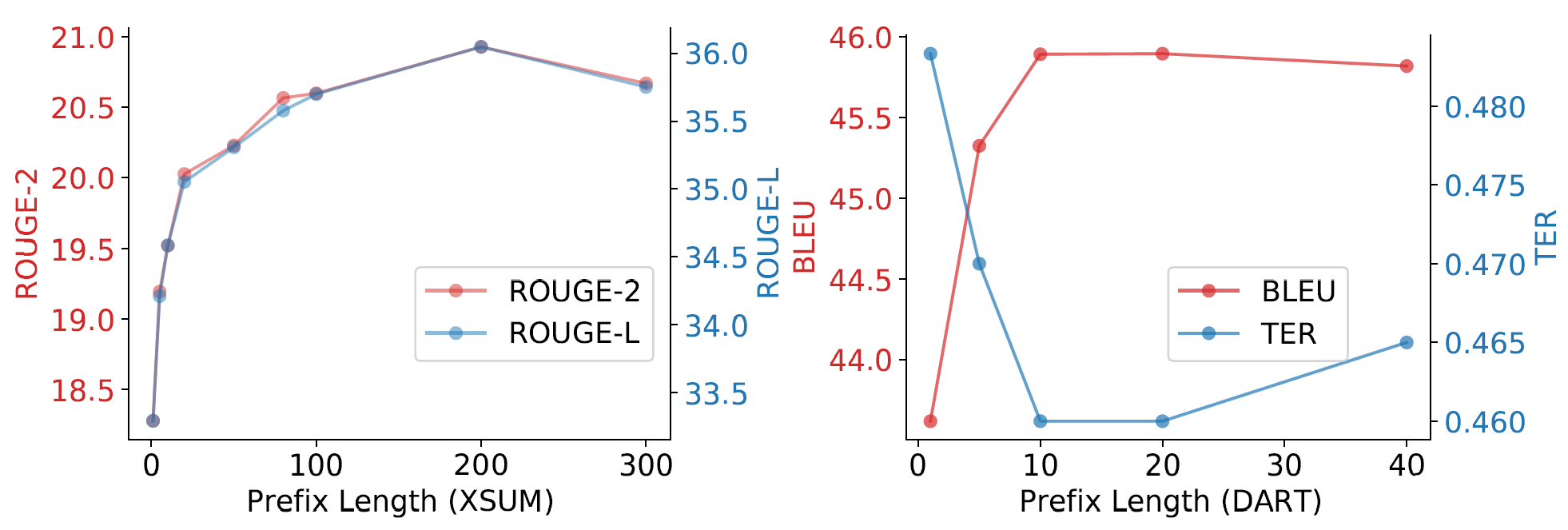
前缀长度会影响微调效果吗?
会。效果会随着长度增加而提升,但是达到某个阈值之后,继续增加长度会使效果变差。不同任务有不同阈值,如下图所示:
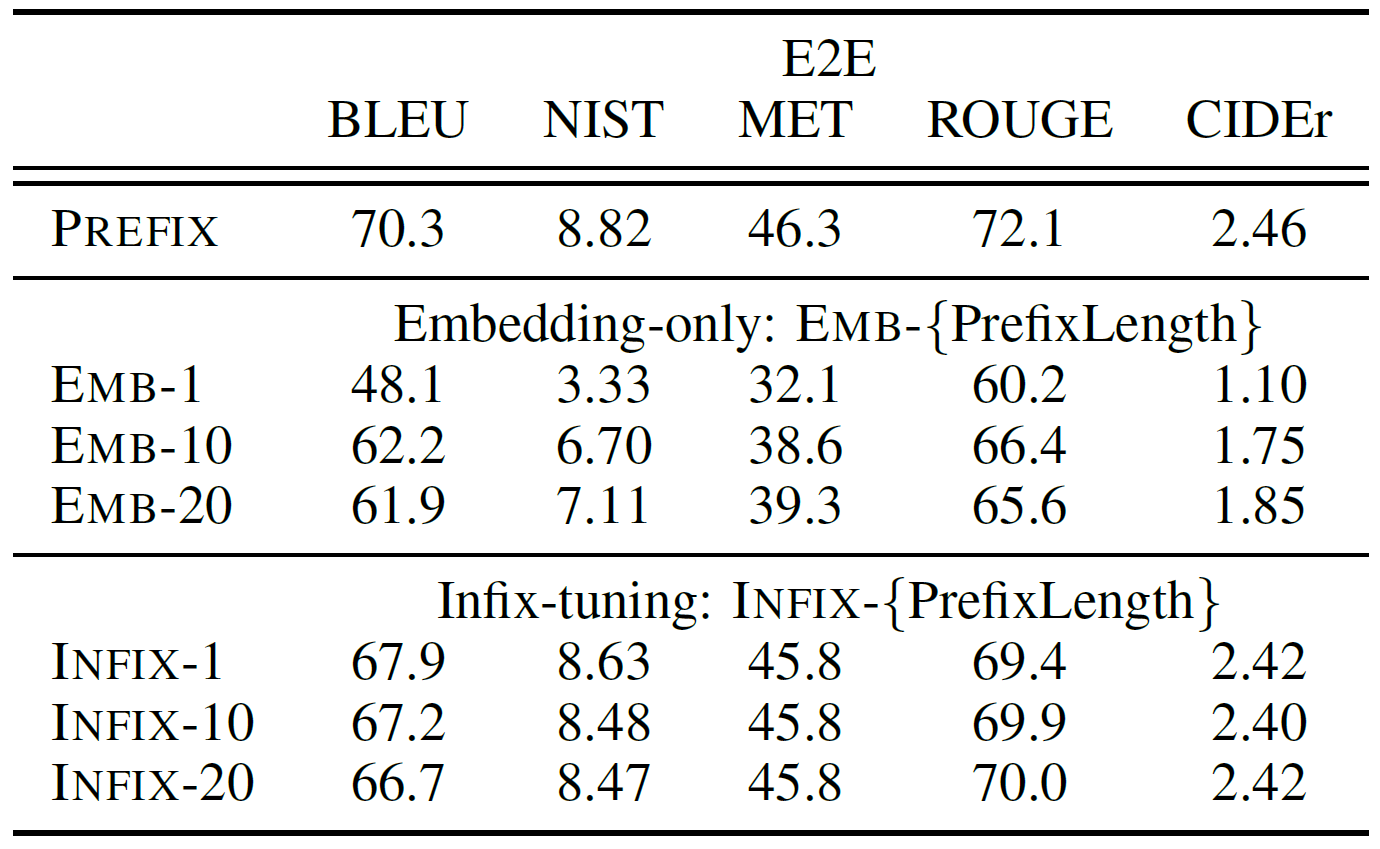
如果只更新嵌入参数,会影响效果吗?prefix tuning的前缀只能放在输入最前面吗?如果把虚拟token放在输入中间,得到新输入\(z=[x;PREFIX;y]\),会影响效果吗?
会。论文做了对比实验,发现只更新嵌入参数(embedding-only)或把虚拟token放在中间(infixing),效果均会变差:
源码
以huggingface peft代码为例,PrefixEncoder可以选择做或不做重参数化:
def __init__(self, config):
super().__init__()
self.prefix_projection = config.prefix_projection
token_dim = config.token_dim
num_layers = config.num_layers
encoder_hidden_size = config.encoder_hidden_size
num_virtual_tokens = config.num_virtual_tokens
if self.prefix_projection and not config.inference_mode:
# Use a two-layer MLP to encode the prefix
self.embedding = torch.nn.Embedding(num_virtual_tokens, token_dim)
self.transform = torch.nn.Sequential(
torch.nn.Linear(token_dim, encoder_hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(encoder_hidden_size, num_layers * 2 * token_dim),
)
else:
self.embedding = torch.nn.Embedding(num_virtual_tokens, num_layers * 2 * token_dim)
def forward(self, prefix: torch.Tensor):
if self.prefix_projection:
prefix_tokens = self.embedding(prefix)
past_key_values = self.transform(prefix_tokens)
else:
past_key_values = self.embedding(prefix)
return past_key_values
如果选择重参数化,在构造函数中定义一个transform变换,在forward中调用transform即可。值得注意的是,无论是否重参数化,PrefixEncoder的输出维度均为num_layers * 2 * token_dim,而不是像PromptEncoder等方法一样返回token_dim维度的输出,这是为什么呢?
乘以num_layers比较好理解,因为prefix tuning在每层前面都要添加参数。为什么要再乘以2呢?
这是因为每层都有K向量和V向量,每个K和V向量的前面都要插入前缀。从PeftModel的get_prompt函数中可以看出,PrefixEncoder返回的past_key_values形状被重置,显然是为了将来把虚拟token向量“分配”到每个注意力头:
# past_key_values = prompt_encoder(prompt_tokens)
past_key_values = past_key_values.view(
batch_size,
peft_config.num_virtual_tokens,
peft_config.num_layers * 2,
peft_config.num_attention_heads,
peft_config.token_dim // peft_config.num_attention_heads,
)
if peft_config.num_transformer_submodules == 2:
past_key_values = torch.cat([past_key_values, past_key_values], dim=2)
past_key_values = past_key_values.permute([2, 0, 3, 1, 4]).split(
peft_config.num_transformer_submodules * 2
)
看到“past_key_values”这样的变量名,立刻会联想到前文介绍过的KV-cache。回想一下,在自回归过程中,当模型计算得到当前token的K和V后,会把K和V缓存起来。以GPT2的代码为例,在GPT2Attention的forward函数中有如下几行:
if layer_past is not None:
past_key, past_value = layer_past
key = torch.cat((past_key, key), dim=-2)
value = torch.cat((past_value, value), dim=-2)
可以看到,past_key和past_value被分别插入到当前key和value的前面。有没有似曾相识?没错,给每一层添加前缀也是类似的操作,前缀的K相当于past_key,前缀的V相当于past_value,前缀的K和V插到每一层K和V的最前面。所以,PrefixEncoder返回值叫past_key_values就合情合理了。
与p-tuning v2的关系
基本上是同一回事,看看p-tuning v2的结构就知道了:
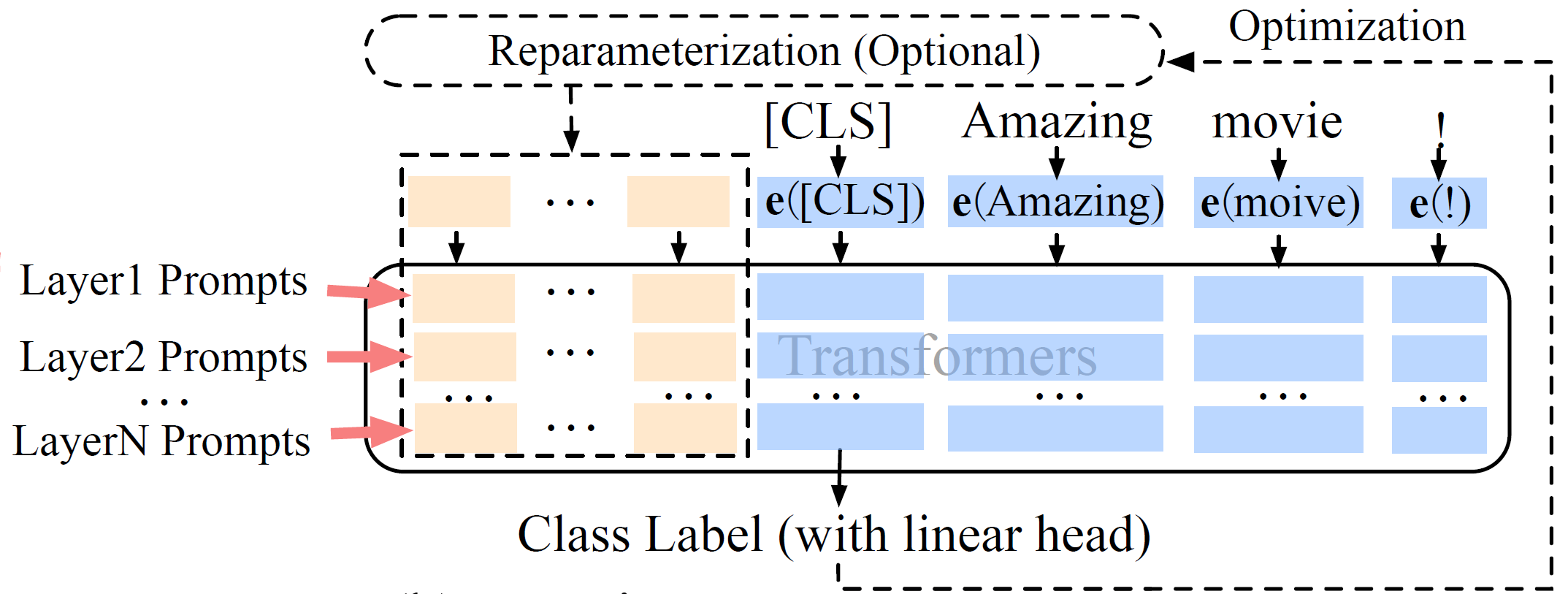
只不过p-tuning v2没有强制嵌入矩阵重参数化。所以,peft没有专门实现p-tuning v2的代码。初始化PrefixEncoder时把self.prefix_projection置为False,就相当于p-tuning v2了。prefix tuning和p-tuning v2两篇论文都发表于2021年,属于撞衫了。